Neulich habe ich mich gefragt, wie genau eigentlich Sortieralgorithmen funktionieren. Das hat mich dazu gebracht, mich näher mit eben diesen zu beschäftigen. Dabei habe ich viel Interessantes gelernt, das ich gerne mit dir teilen möchte.
In diesem Beitrag werde ich verschiedene Sortieralgorithmen vorstellen und ihre Funktionsweise anhand von Python-Code und anschaulichen Grafiken erklären. Ich werde mir sowohl bekannte Algorithmen wie Bubblesort und Quicksort als auch ungewöhnlichere Vertreter wie Bogosort ansehen. Dabei werde ich auch auf die Geschwindigkeit der Algorithmen eingehen und herausfinden, welche sich für welche Anwendungsfälle eignen.
 Alle Sortiervorgänge im Vergleich
Alle Sortiervorgänge im Vergleich
Warum sind Sortieralgorithmen wichtig?
Sortieralgorithmen spielen in der Informatik eine wichtige Rolle. Sie werden überall dort eingesetzt, wo Daten geordnet werden müssen, z.B. in Datenbanken, Suchmaschinen oder bei der Verarbeitung großer Datenmengen. Effiziente Sortieralgorithmen können die Geschwindigkeit von Anwendungen erheblich verbessern.
Im nächsten Abschnitt werde ich zunächst einen Datensatz erstellen, den ich dann mit verschiedenen Sortieralgorithmen bearbeiten werde.
Der zu sortierende Datensatz
Es wird ein einfacher Datensatz sein, den man hoffentlich gut visualisieren kann. Und zwar eine gewisse Anzahl von Integerwerten, die jedes Mal gleich randomisiert sein sollten. Eine Visualisierung folgt gleich.
# Zunächst werden alle benötigten Bibliotheken importiert
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import random
import os
import time
# Random Seed setzen
random.seed(42)# Anzahl der Elemente im Datensatz
n = 50
# Datensatz generieren
dataset = random.sample(range(1, n+1), n)Dann definiere ich eine Funktion, die ich noch häufiger einsetzen werde, um das Sortieren zu visualisieren.
cmap = cm.get_cmap('YlGnBu') # Farbverlauf von Gelb über Grün zu Blau
# Funktion zum Aktualisieren des Balkendiagramms
def update_chart(data, iteration, xlim, ylim, folder_name, name = "Dataset",):
i = len(data)
colors = [cmap(x/i) for x in data]
plt.bar(range(1, i+1), data, color=colors)
plt.xlim(xlim)
plt.ylim(ylim)
plt.xticks([])
plt.yticks([])
if not os.path.exists(folder_name):
os.makedirs(folder_name)
if name == "Start":
plt.title(f'Startkonfiguration')
plt.savefig(f'{folder_name}/{name}.png')
else:
plt.title(f'{name} - Step {iteration}')
plt.savefig(f'{folder_name}/{name}_Iteration_{iteration:04d}.png') # Speichere den Plot als PNG-Datei
plt.close()Theoretisch muss man den Plot natürlich nicht abspeichern. Für meinen Workflow beim Erstellen dieses Beitrages ist das hingegen sehr hilfreich. Und dann wird die Funktion auch schon das erste Mal aufgerufen.
update_chart(dataset, 1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen", name="Start")Im Anschuss rufe ich den Plot wieder auf. Hier kannst du den unsortierten Datensatz erkennen, bestehend aus Integerwerten.
# Load the image
image = plt.imread('Sortieralgorithmen/Start.png')
# Show the image
plt.imshow(image)
plt.axis('off')
plt.show() Startkonfiguration: Mit diesem Datensatz startet jeder Sortieralgorithmus
Startkonfiguration: Mit diesem Datensatz startet jeder Sortieralgorithmus
Sortieralgorithmen
Im folgenden werde ich ein paar Sortieralgorithmen vorstellen, die so weit ich weiß, zu den gängigsten gehören. Ich werde zu jedem Algorithmus ein paar Worte verlieren und den Algorithmus anschließend implementieren. Da ich den Sortiervorgang auch visualisieren möchte, werde ich ein paar zusätzliche, für den Algorithmus unnötige Zeilen programmieren. Ich habe versucht das alles konsistent zu halten, aber weil dieser Beitrag mit einigen Pausen entstanden ist, gibt es hier und da vermutlich ein paar Ausreißer.
Bubble Sort
Bubble Sort ist ein einfacher Vergleichssortieralgorithmus, der wiederholt benachbarte Elemente vergleicht und sie vertauscht, wenn sie in der falschen Reihenfolge sind. Dieser Prozess wird so lange fortgesetzt, bis keine Vertauschungen mehr nötig sind, was bedeutet, dass das Array sortiert ist. Der Name “Bubble Sort” kommt daher, dass kleinere Elemente wie Blasen im Wasser nach oben steigen, genau wie die zu sortierenden Elemente aufsteigen.
- Funktionsweise: In jedem Durchlauf wird das Array von Anfang bis Ende durchlaufen. Dabei werden jeweils zwei benachbarte Elemente verglichen. Wenn das linke Element größer ist als das rechte, werden sie vertauscht. Am Ende des ersten Durchlaufs befindet sich das größte Element am Ende des Arrays. Im zweiten Durchlauf wird das zweitgrößte Element gefunden und so weiter.
- Zeitkomplexität: Die Zeitkomplexität von Bubble Sort ist im Durchschnitt und im schlimmsten Fall , wobei die Anzahl der Elemente im Array ist. Für große Datensätze kann Bubble Sort daher sehr ineffizient sein und wird in der Praxis oft durch schnellere Sortieralgorithmen wie Quick Sort, Merge Sort oder Heap Sort ersetzt.
- Besonderheiten: Bubble Sort ist einfach zu verstehen und zu implementieren, aber ineffizient für große Datensätze. Er ist ein stabiler Sortieralgorithmus, d.h., die relative Reihenfolge gleicher Elemente bleibt erhalten.
 Bubblesort Sortiervorgang
Bubblesort Sortiervorgang
Theoretich existiert der zu sortierende Datensatz bereits. Der Vollständigkeit halber, werde ich ihn dennoch jedes Mal erzeugen.
# Erzeuge einen zufälligen Datensatz
n = 50
dataset = random.sample(range(1, n+1), n)Als nächstes definiere ich die Funktion mit dem Sortieralgorithmus.
def bubble_sort(data):
"""
Implementiert den Bubble-Sort-Algorithmus und speichert Snapshots des Arrays nach jedem Swap. Dieser Algorithmus
sortiert eine Liste von Zahlen, indem er wiederholt durch die Liste geht, vergleicht jedes Paar benachbarter
Elemente und tauscht sie, wenn sie in der falschen Reihenfolge sind.
Args:
data (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
sorted_datasets (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Swap enthält.
"""
def swap(i, j):
"""
Hilfsfunktion für den Bubble-Sort-Algorithmus. Sie vertauscht die Elemente an den Positionen i und j.
Args:
i (int): Der Index des ersten Elements.
j (int): Der Index des zweiten Elements.
"""
data[i], data[j] = data[j], data[i] # Tausche die Elemente an den Positionen i und j
sorted_datasets = [] # Initialisiere eine leere Liste, um die sortierten Datensätze zu speichern
n = len(data) # Die Anzahl der Elemente im Datensatz
for i in range(n): # Für jedes Element im Datensatz
for j in range(0, n-i-1): # Für jedes Element, das noch nicht sortiert ist
if data[j] > data[j+1]: # Wenn das aktuelle Element größer als das nächste Element ist
swap(j, j+1) # Tausche die beiden Elemente
sorted_datasets.append(data[:]) # Speichere den aktuellen Zustand des Datensatzes
return sorted_datasets # Gib die Liste der sortierten Datensätze zurückIm Anschluss an die Definition der Sortieralgorithmen in diesem Beitrag, wird jeder dieser Algorithmen ausgeführt. Während jeder Sortierschritt durchlaufen wird, wird eine Visualisierungsfunktion aufgerufen, die den aktuellen Zustand des Sortierprozesses als PNG-Bild speichert. Am Ende des Beitrags wird aus diesen Bildern ein GIF für jeden Sortiervorgang erstellt, ebenfalls mit Python. Das erste dieser GIFs ist bereits oben im Beitrag zu sehen.
for i, data in enumerate(bubble_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/bubble_sort", name="Bubblesort")Das was ich hier für Bubble Sort ausgeführt habe, führe ich so auch für die anderen Sortiervorgänge durch, werde es aber nicht mehr entsprechend kommentieren.
Insertion Sort
Insertion Sort baut das sortierte Array schrittweise auf, indem er jedes Element aus dem unsortierten Teil nimmt und es an der richtigen Stelle im sortierten Teil einfügt.
- Funktionsweise: Der Algorithmus beginnt mit dem zweiten Element und vergleicht es mit dem ersten Element. Wenn es kleiner ist, wird es vor dem ersten Element eingefügt. Dann wird das dritte Element genommen und mit den beiden ersten verglichen und so weiter. Am Ende jedes Schritts ist der linke Teil des Arrays sortiert.
- Zeitkomplexität: im Durchschnitt und im schlimmsten Fall. Allerdings ist Insertion Sort effizienter als Bubble Sort, wenn das Array bereits teilweise sortiert ist. In diesem Fall muss jedes Element nur eine kurze Distanz bewegt werden, um an die richtige Position zu gelangen. Daher kann die Zeitkomplexität von Insertion Sort in solchen Fällen nahe an liegen. Das gilt nur für teilweise sortierte Arrays. Für zufällig sortierte Arrays ist die Zeitkomplexität von Insertion Sort immer noch .
- Besonderheiten: Insertion Sort ist ein In-place-Algorithmus, d.h., er benötigt keinen zusätzlichen Speicherplatz. Er ist einfach zu implementieren und effizient für kleine Datensätze oder fast sortierte Daten.
 Insertionsort Sortiervorgang
Insertionsort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
n = 50
dataset = random.sample(range(1, n+1), n)def insertion_sort(data):
"""
Implementiert den Insertion-Sort-Algorithmus und speichert Snapshots des Arrays nach jedem Insert. Dieser Algorithmus
sortiert eine Liste von Zahlen, indem er jedes Element an der richtigen Position in der bereits sortierten Teilmenge
der Liste einfügt.
Args:
data (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
sorted_datasets (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Insert enthält.
"""
def insert(j, key):
"""
Hilfsfunktion für den Insertion-Sort-Algorithmus. Sie verschiebt Elemente nach rechts und fügt das
Schlüsselelement an der richtigen Position ein.
Args:
j (int): Der Index, an dem das Schlüsselelement eingefügt werden soll.
key (int): Das Schlüsselelement, das eingefügt werden soll.
"""
while j >= 0 and data[j] > key: # Solange wir nicht am Anfang des Arrays sind und das aktuelle Element größer als das Schlüsselelement ist
data[j+1] = data[j] # Verschiebe das aktuelle Element nach rechts
j -= 1 # Gehe zum nächsten Element auf der linken Seite
data[j+1] = key # Füge das Schlüsselelement an der richtigen Position ein
sorted_datasets = [] # Initialisiere eine leere Liste, um die sortierten Datensätze zu speichern
for i in range(1, len(data)): # Starte bei der zweiten Position im Array
insert(i - 1, data[i]) # Füge das Element `data[i]` an der richtigen Position ein
sorted_datasets.append(data[:]) # Speichere den aktuellen Zustand des Arrays
return sorted_datasets # Gib die Liste der sortierten Datensätze zurückfor i, data in enumerate(insertion_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/insertion_sort", name="Insertionsort")Selection Sort
Selection Sort findet in jedem Durchlauf das kleinste Element im unsortierten Teil des Arrays und tauscht es mit dem ersten Element des unsortierten Teils.
- Funktionsweise: Der Algorithmus durchläuft das Array und findet das kleinste Element. Dieses wird mit dem ersten Element vertauscht. Dann wird der Vorgang für den restlichen, unsortierten Teil des Arrays wiederholt.
- Zeitkomplexität: in allen Fällen. Die Anzahl der Vergleiche ist unabhängig von der Anordnung der Elemente immer gleich.
- Besonderheiten: Selection Sort ist einfach zu verstehen und implementieren, aber es ist nicht effizient für große Datensätze. Ein Vorteil von Selection Sort gegenüber einigen anderen Sortieralgorithmen wie Bubble Sort ist, dass es die Anzahl der Vertauschungen minimiert, was nützlich sein kann, wenn das Vertauschen von Elementen eine teure Operation ist.
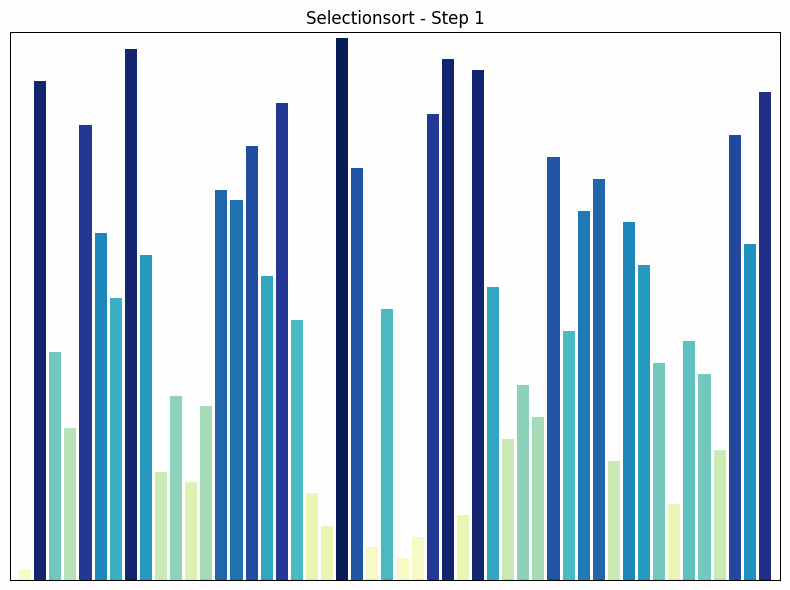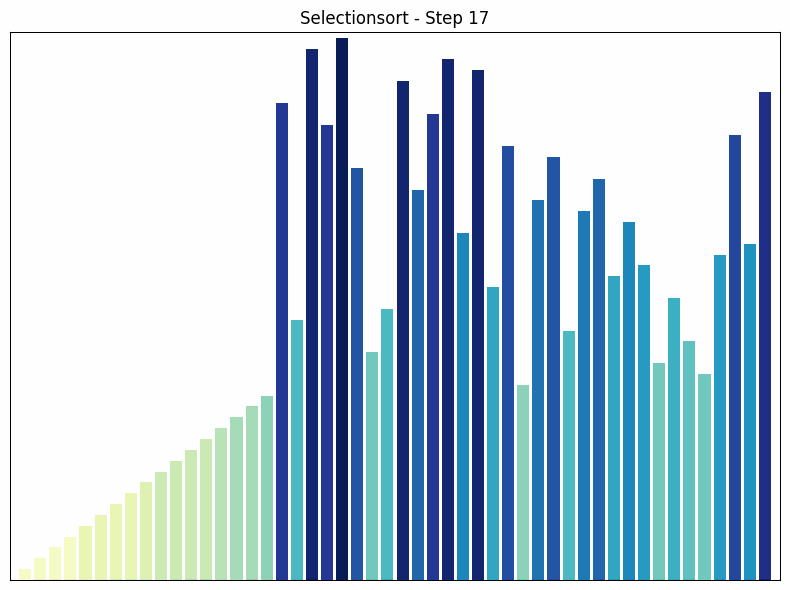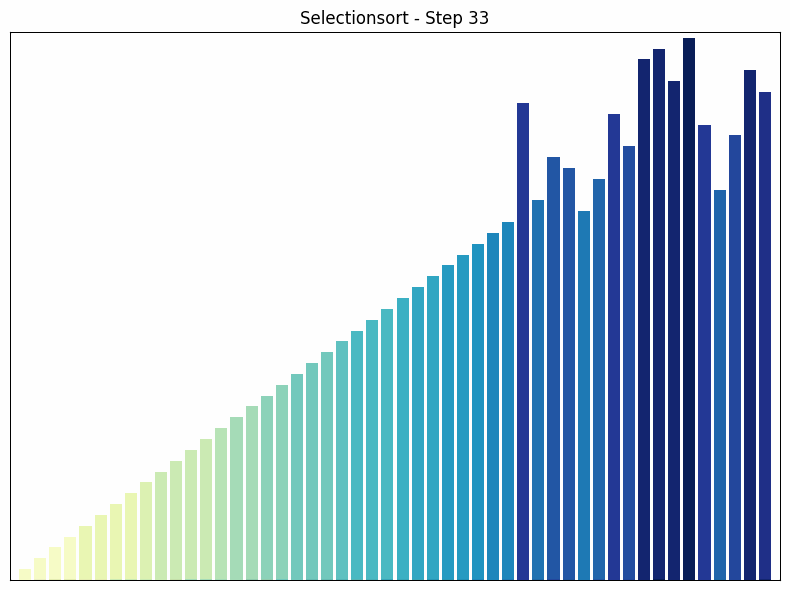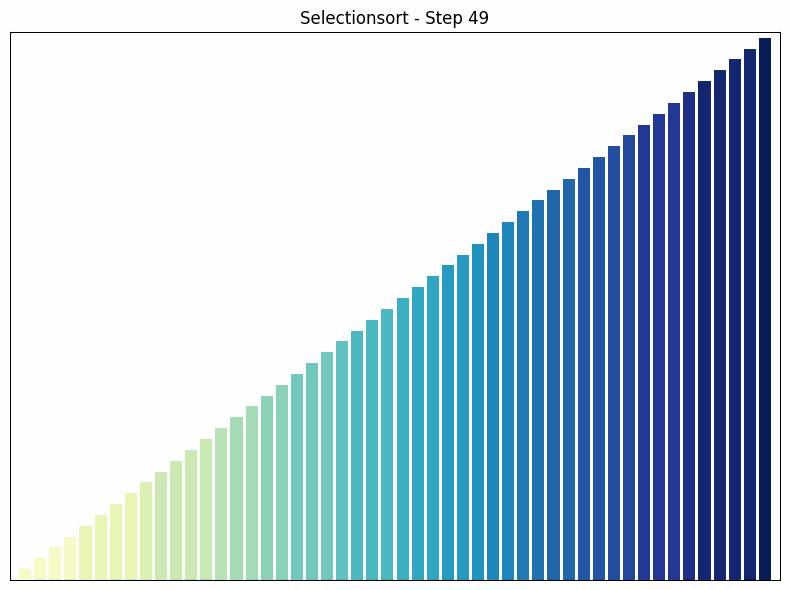 Selectionsort Sortiervorgang
Selectionsort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
n = 50
dataset = random.sample(range(1, n+1), n)def selection_sort(data):
"""
Implementiert den Selection-Sort-Algorithmus und speichert Snapshots des Arrays nach jedem Swap. Dieser Algorithmus
sortiert eine Liste von Zahlen, indem er das kleinste Element findet und es mit dem ersten Element tauscht,
dann das zweitkleinste Element findet und es mit dem zweiten Element tauscht, und so weiter.
Args:
data (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
sorted_datasets (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Swap enthält.
"""
def find_min_index(start_index):
"""
Hilfsfunktion für den Selection-Sort-Algorithmus. Sie findet den Index des kleinsten Elements ab dem
gegebenen Startindex.
Args:
start_index (int): Der Startindex für die Suche.
Returns:
min_index (int): Der Index des kleinsten Elements ab dem Startindex.
"""
min_index = start_index
for j in range(start_index+1, len(data)):
if data[j] < data[min_index]:
min_index = j
return min_index
sorted_datasets = [] # Initialisiere eine leere Liste, um die sortierten Datensätze zu speichern
for i in range(len(data)-1): # Für jedes Element im Datensatz, außer dem letzten
min_index = find_min_index(i) # Finde den Index des kleinsten Elements ab dem aktuellen Index
data[i], data[min_index] = data[min_index], data[i] # Tausche das aktuelle Element mit dem kleinsten Element
sorted_datasets.append(data[:]) # Speichere den aktuellen Zustand des Datensatzes
return sorted_datasets # Gib die Liste der sortierten Datensätze zurückfor i, data in enumerate(selection_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/selection_sort", name="Selectionsort")Merge Sort
Merge Sort ist ein “Teile und Herrsche”-Algorithmus, der das Array rekursiv in zwei Hälften teilt, jede Hälfte sortiert und dann die sortierten Hälften zusammenführt.
- Funktionsweise: Das Array wird solange halbiert, bis nur noch einzelne Elemente übrig sind. Diese sind trivialerweise sortiert. Dann werden die einzelnen Elemente zu sortierten Paaren zusammengeführt, dann Paare zu Vierergruppen und so weiter, bis das gesamte Array sortiert ist.
- Zeitkomplexität: Die Zeitkomplexität von Merge Sort ist in allen Fällen , da das Array in jedem Schritt halbiert wird und dann die beiden Hälften in Zeit zusammengeführt werden. Dies macht Merge Sort effizient für große Datensätze.
- Besonderheiten: Merge Sort ist ein stabiler Sortieralgorithmus, was bedeutet, dass gleichwertige Elemente in der sortierten Ausgabe die gleiche relative Reihenfolge haben wie in der Eingabe. Ein Nachteil von Merge Sort ist, dass er zusätzlichen Speicherplatz benötigt, um die beiden Hälften beim Zusammenführen zu speichern.
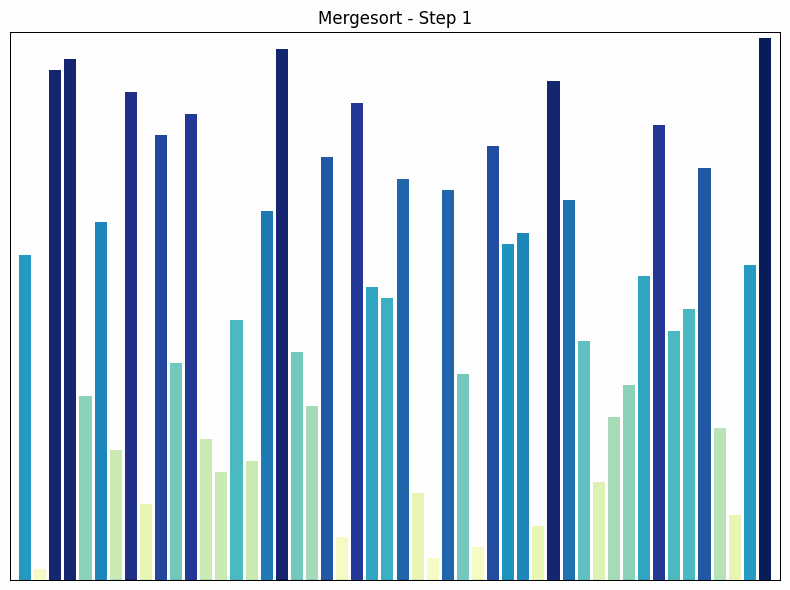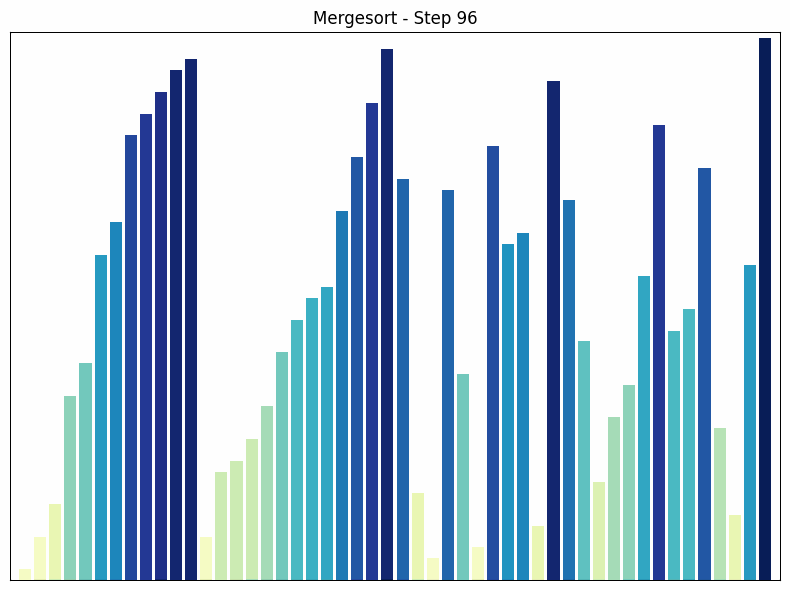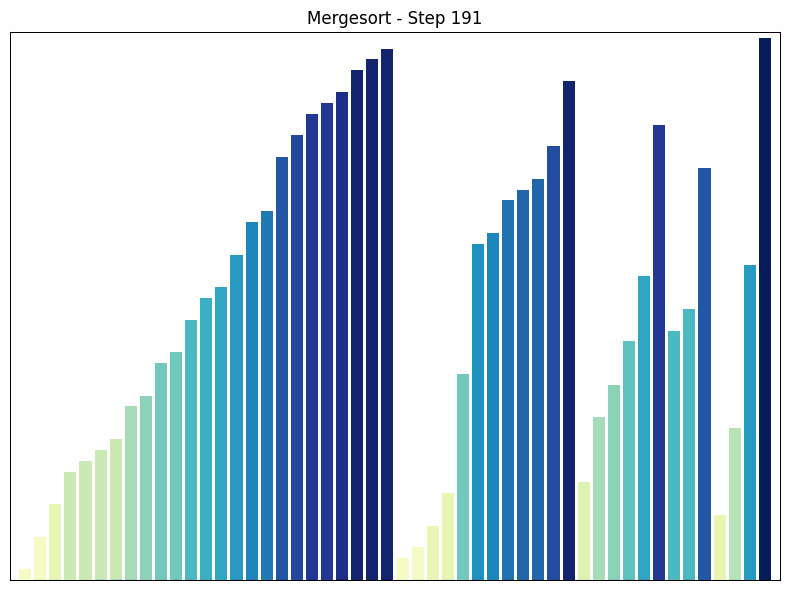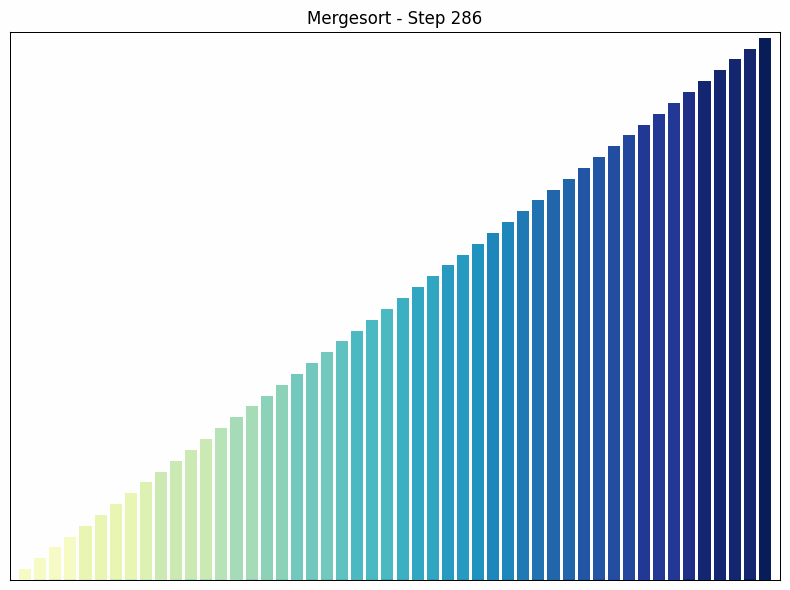 Mergesort Sortiervorgang
Mergesort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
n = 50
dataset = random.sample(range(1, n+1), n)import itertools
def merge_sort(data):
"""
Implementiert den Merge-Sort-Algorithmus und speichert Snapshots des Arrays nach jedem Merge. Dieser Algorithmus
sortiert eine Liste von Zahlen, indem er sie in zwei Hälften teilt, jede Hälfte sortiert und dann die sortierten
Hälften zusammenführt.
Args:
data (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
steps (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Merge enthält.
"""
steps = [] # Liste zur Speicherung der Zwischenschritte
def merge(left, right, start):
"""
Hilfsfunktion für den Merge-Sort-Algorithmus. Sie führt zwei sortierte Listen zusammen und speichert
Snapshots des Arrays nach jedem Merge.
Args:
left (list): Die linke sortierte Liste.
right (list): Die rechte sortierte Liste.
start (int): Der Startindex für das Zusammenführen im ursprünglichen Array.
Returns:
result (list): Die zusammengeführte und sortierte Liste.
"""
result = [] # Ergebnisliste
i = j = 0 # Initialisiere die Indizes für die linke und rechte Liste
# Durchlaufe beide Listen und füge das kleinere Element zur Ergebnisliste hinzu
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# Aktualisiere den entsprechenden Teil des ursprünglichen Arrays und speichere den Schritt
data[start:start+len(result)] = result
steps.append(list(data))
# Füge die verbleibenden Elemente von left oder right hinzu
for value in itertools.chain(left[i:], right[j:]):
result.append(value)
data[start:start+len(result)] = result
steps.append(list(data))
return result # Gib die sortierte Liste zurück
def sort(data, start=0):
"""
Hilfsfunktion für den Merge-Sort-Algorithmus. Sie teilt das Array in zwei Hälften, sortiert jede Hälfte
und führt sie dann zusammen.
Args:
data (list): Das Array, das sortiert werden soll.
start (int): Der Startindex für das Sortieren im ursprünglichen Array.
Returns:
list: Die sortierte Liste.
"""
if len(data) <= 1: # Wenn die Liste nur ein Element enthält, ist sie bereits sortiert
return data
mid = len(data) // 2 # Finde den mittleren Index
left = data[:mid] # Teile die Liste in zwei Hälften
right = data[mid:]
# Sortiere beide Hälften und führe sie zusammen
return merge(sort(left, start), sort(right, start + mid), start)
sort(data) # Starte den Sortierprozess
return steps # Gib die Liste der Zwischenschritte zurückfor i, data in enumerate(merge_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/merge_sort", name="Mergesort")Quick Sort
Quick Sort ist ein weiterer “Teile und Herrsche”-Algorithmus. Er wählt ein Element als “Pivot” und partitioniert das Array in zwei Teilbereiche: Elemente kleiner als das Pivot und Elemente größer als das Pivot. Anschließend werden die Teilbereiche rekursiv sortiert.
- Funktionsweise: Der Algorithmus wählt ein Element als “Pivot” und teilt das Array in zwei Teilbereiche: Elemente kleiner als das Pivot und Elemente größer als das Pivot. Diese Teilbereiche werden dann rekursiv sortiert. Die Wahl des Pivots kann die Effizienz des Algorithmus stark beeinflussen.
- Zeitkomplexität: Die durchschnittliche Zeitkomplexität von Quick Sort ist , aber im schlimmsten Fall (wenn das kleinste oder größte Element als Pivot gewählt wird) kann sie auf ansteigen.
- Besonderheiten: Quick Sort ist ein In-place-Algorithmus, was bedeutet, dass er keinen zusätzlichen Speicherplatz benötigt. Er ist in der Praxis oft schneller als Merge Sort, obwohl seine Zeitkomplexität im schlechtesten Fall höher ist. Ein Nachteil von Quick Sort ist, dass er nicht stabil ist, d.h., gleichwertige Elemente können ihre relative Reihenfolge während der Sortierung ändern.
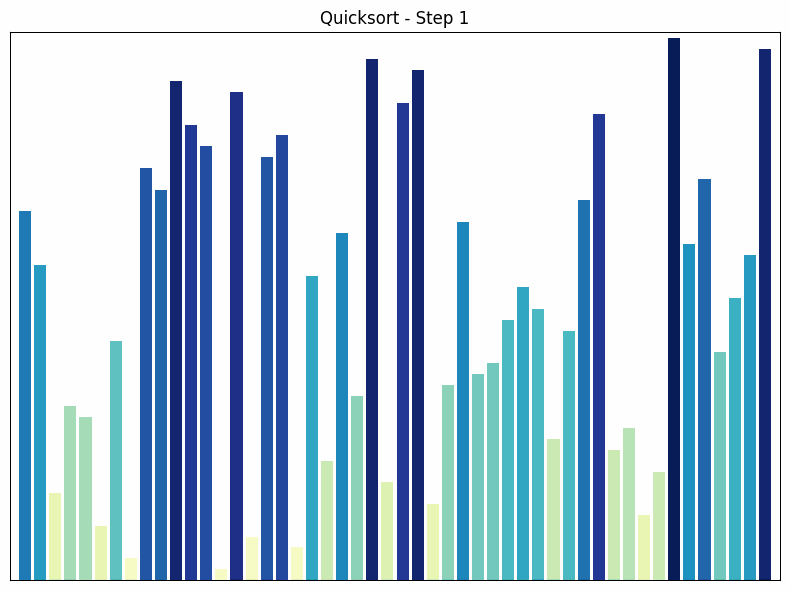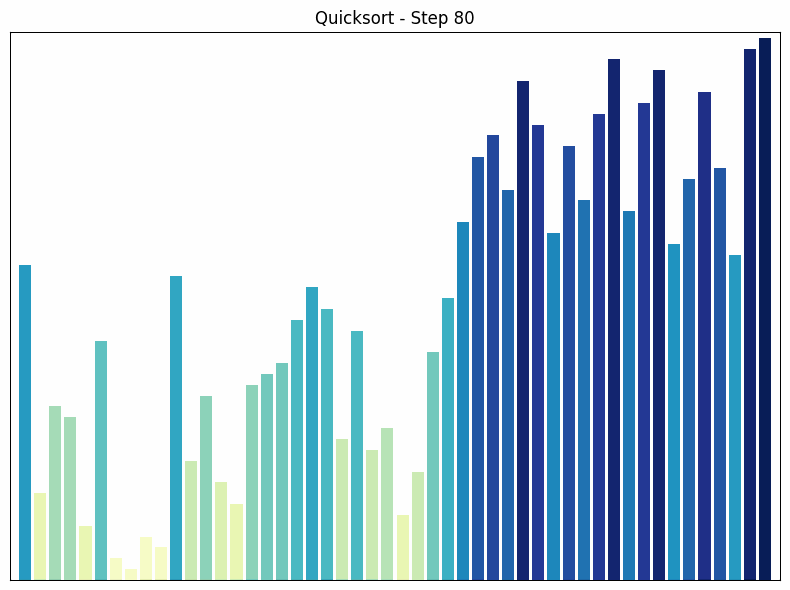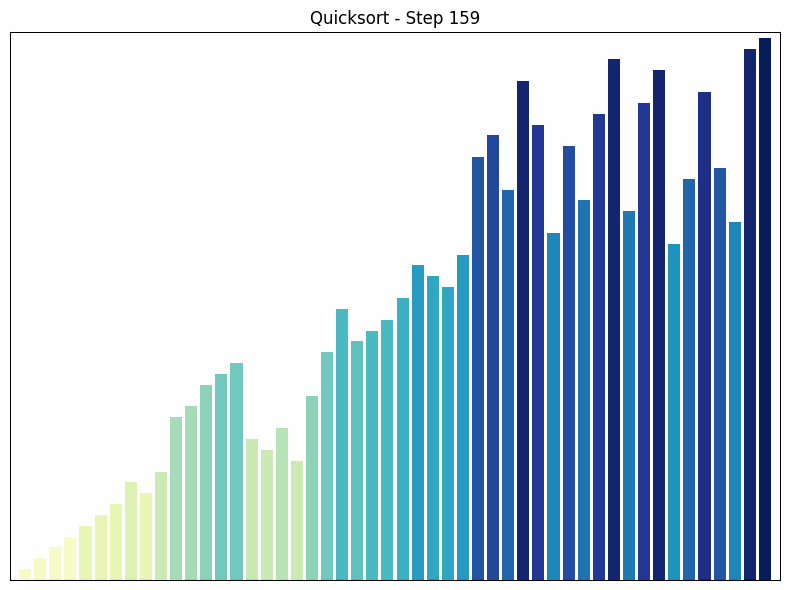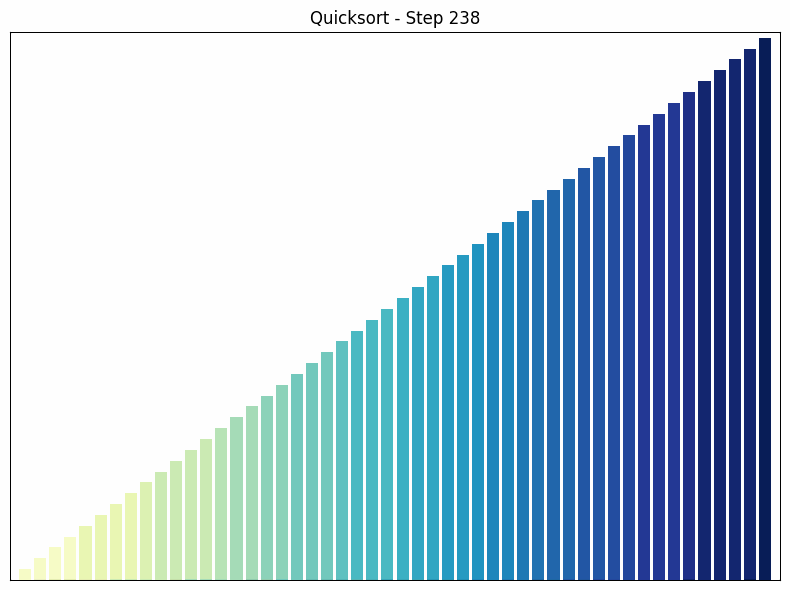 Quicksort Sortiervorgang
Quicksort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
n = 50
dataset = random.sample(range(1, n+1), n)def quick_sort_visualized(arr):
"""
Implementiert den Quick-Sort-Algorithmus und speichert Snapshots des Arrays nach jedem Swap. Dieser Algorithmus
sortiert eine Liste von Zahlen, indem er ein "Pivot"-Element auswählt und alle Elemente, die kleiner sind,
links vom Pivot und alle Elemente, die größer sind, rechts vom Pivot anordnet. Dieser Prozess wird dann
rekursiv auf die linke und rechte Hälfte des Arrays angewendet.
Args:
arr (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
snapshots (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Swap enthält.
"""
snapshots = [arr[:]] # Initialer Snapshot vor Beginn der Sortierung
def _quick_sort(arr, low, high):
"""
Hilfsfunktion für den Quick-Sort-Algorithmus. Sie führt den eigentlichen Sortierprozess durch und ruft
sich selbst rekursiv auf die linke und rechte Hälfte des Arrays auf.
Args:
arr (list): Das Array, das sortiert werden soll.
low (int): Der Startindex des Teils des Arrays, der sortiert werden soll.
high (int): Der Endindex des Teils des Arrays, der sortiert werden soll.
"""
if low < high:
pivot_index = partition(arr, low, high)
snapshots.append(arr[:]) # Snapshot nach jeder Swap-Operation
_quick_sort(arr, low, pivot_index - 1)
_quick_sort(arr, pivot_index + 1, high)
def partition(arr, low, high):
"""
Hilfsfunktion für den Quick-Sort-Algorithmus. Sie wählt ein Pivot-Element und ordnet alle Elemente, die
kleiner sind, links vom Pivot und alle Elemente, die größer sind, rechts vom Pivot an.
Args:
arr (list): Das Array, das sortiert werden soll.
low (int): Der Startindex des Teils des Arrays, der sortiert werden soll.
high (int): Der Endindex des Teils des Arrays, der sortiert werden soll.
Returns:
int: Der Index des Pivot-Elements nach der Partitionierung.
"""
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
snapshots.append(arr[:]) # Snapshot nach jedem Swap
arr[i + 1], arr[high] = arr[high], arr[i + 1]
snapshots.append(arr[:]) # Snapshot nach dem finalen Swap
return i + 1
_quick_sort(arr, 0, len(arr) - 1)
return snapshotsfor i, data in enumerate(quick_sort_visualized(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/quick_sort", name="Quicksort")Heap Sort
Heap Sort nutzt eine spezielle Datenstruktur namens Heap, um das Array zu sortieren. Ein Heap ist ein binärer Baum, in dem jeder Knoten größer (oder kleiner, je nach Implementierung) ist als seine Kinder.
- Funktionsweise: Der Heap Sort Algorithmus beginnt mit der Umwandlung des Arrays in einen Heap. Dann wird das größte Element (die Wurzel des Heaps) entfernt und an das Ende des Arrays gestellt. Dieser Prozess wird wiederholt, bis das gesamte Array sortiert ist. Nach jedem Entfernen wird der Heap wiederhergestellt, um die Heap-Eigenschaft zu erhalten.
- Zeitkomplexität: Die Zeitkomplexität von Heap Sort ist in allen Fällen. Dies liegt daran, dass das Erstellen des Heaps Zeit benötigt und das Entfernen jedes Elements Zeit benötigt.
- Besonderheiten: Heap Sort ist ein In-place-Algorithmus, was bedeutet, dass er keinen zusätzlichen Speicherplatz benötigt. Er garantiert eine Zeitkomplexität von , unabhängig von der Anordnung der Elemente. Ein Nachteil von Heap Sort ist, dass er komplexer zu implementieren ist als andere Sortieralgorithmen wie Quick Sort oder Merge Sort.
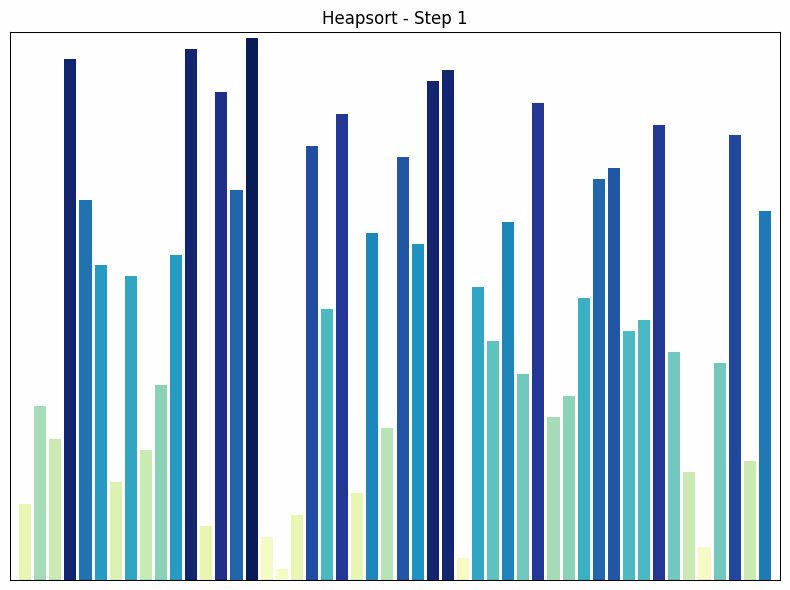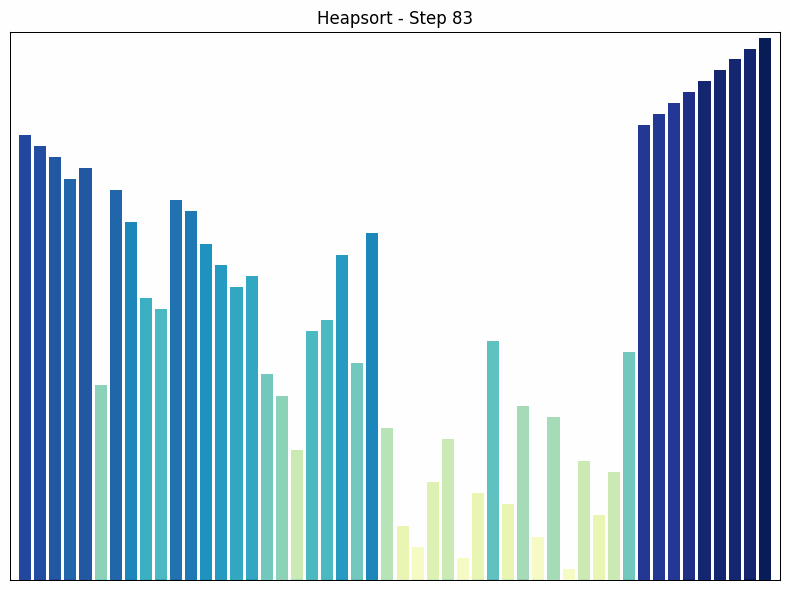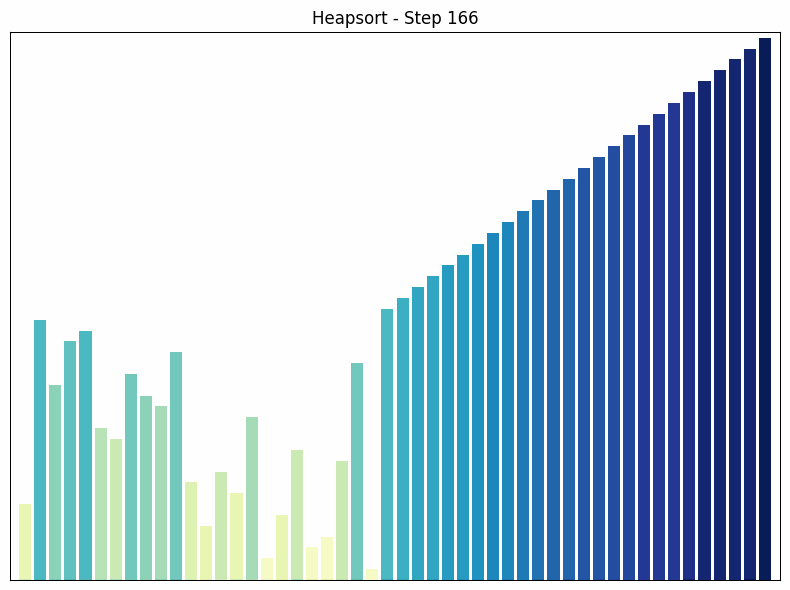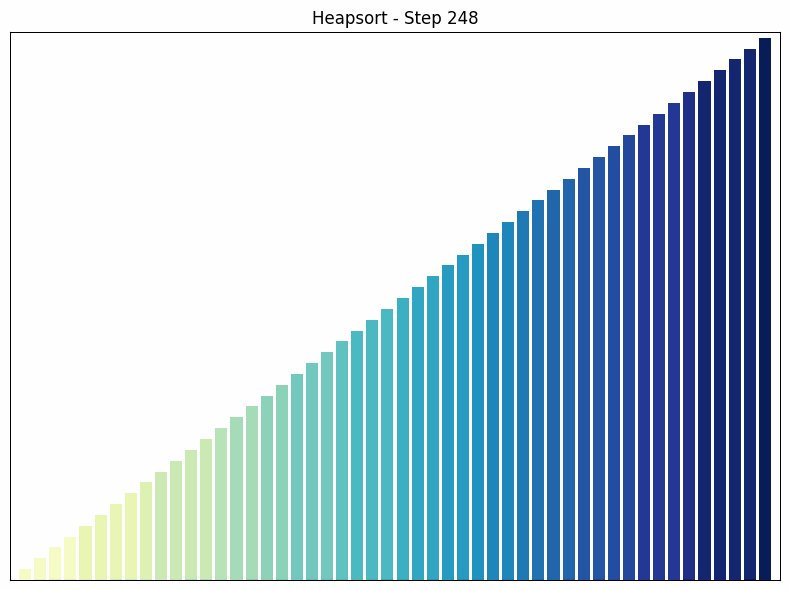 Heapsort Sortiervorgang
Heapsort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
dataset = random.sample(range(1, n+1), n)def heapify(arr, n, i, snapshots):
"""
Hilfsfunktion für den Heap-Sort-Algorithmus. Sie nimmt ein Array und verwandelt es in einen Heap, indem sie
sicherstellt, dass das Element an der Position i größer ist als seine Kinder. Wenn dies nicht der Fall ist,
wird das Element mit dem größten Kind getauscht und der Prozess wird rekursiv fortgesetzt.
Args:
arr (list): Das Array, das in einen Heap umgewandelt werden soll.
n (int): Die Anzahl der Elemente im Array.
i (int): Der Index des Elements, das "heapified" werden soll.
snapshots (list): Eine Liste, die den Zustand des Arrays nach jedem Schritt speichert.
"""
def heap_sort(arr):
"""
Implementiert den Heap-Sort-Algorithmus. Dieser Algorithmus sortiert eine Liste von Zahlen, indem er sie
zuerst in einen Heap umwandelt und dann die Elemente des Heaps in absteigender Reihenfolge entfernt und
an das Ende der Liste anfügt.
Args:
arr (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
snapshots (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Schritt enthält.
"""
n = len(arr)
snapshots = [arr.copy()] # Initialen Zustand speichern
# Heap erstellen (Bottom-up)
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i, snapshots)
# Ein Element nach dem anderen aus dem Heap entfernen und an die richtige Stelle setzen
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # Tausche Wurzel mit letztem Element
snapshots.append(arr.copy()) # Snapshot speichern
heapify(arr, i, 0, snapshots) # Heap wiederherstellen
return snapshotsfor i, data in enumerate(heap_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/heap_sort", name="Heapsort")Radix Sort
Radix Sort sortiert Zahlen nach ihren einzelnen Ziffern, beginnend mit der niedrigsten Stelle (Einerstelle).
- Funktionsweise: Radix Sort sortiert Zahlen basierend auf ihren einzelnen Ziffern, beginnend mit der niedrigsten Stelle (Einerstelle). In jedem Durchlauf werden die Zahlen in “Buckets” einsortiert, basierend auf der Ziffer an der aktuellen Stelle. Dann werden die Buckets in der richtigen Reihenfolge wieder zusammengefügt. Dieser Prozess wird für jede Stelle wiederholt, bis alle Stellen sortiert sind.
- Zeitkomplexität: Die Zeitkomplexität von Radix Sort ist , wobei n die Anzahl der Elemente und k die maximale Anzahl von Stellen ist. Dies macht Radix Sort sehr effizient, wenn die Anzahl der Ziffern begrenzt ist.
- Besonderheiten: Radix Sort ist besonders effizient für ganze Zahlen mit begrenzter Stellenanzahl. Es ist kein vergleichsbasierter Algorithmus, sondern nutzt die Verteilung der Ziffern, um die Zahlen zu sortieren. Dies unterscheidet Radix Sort von vielen anderen Sortieralgorithmen, die auf Vergleichen basieren.
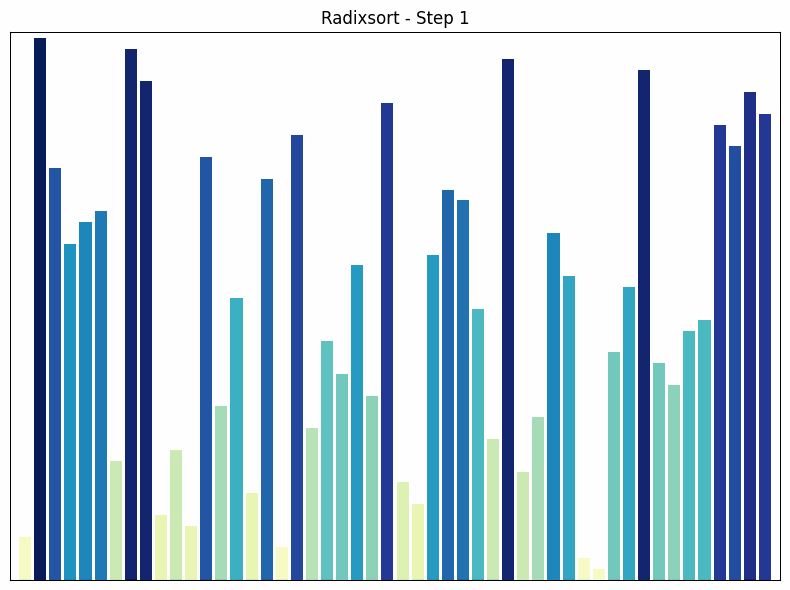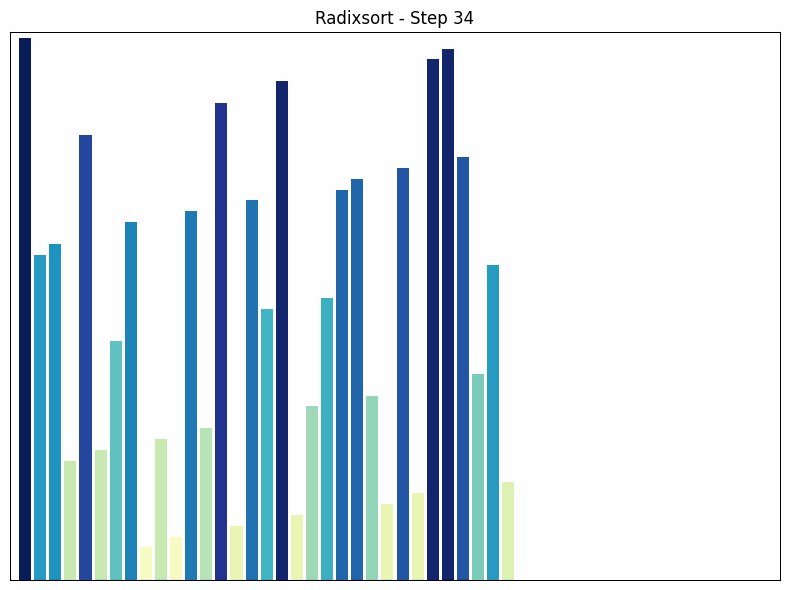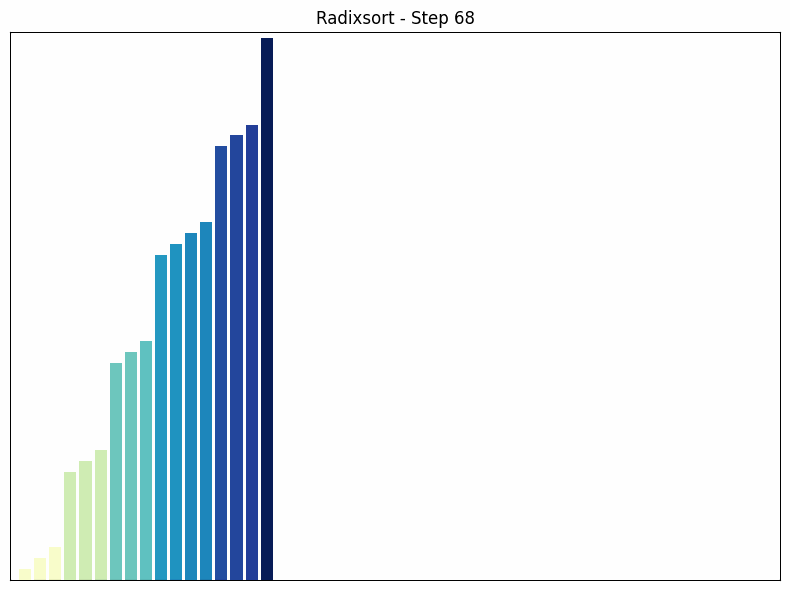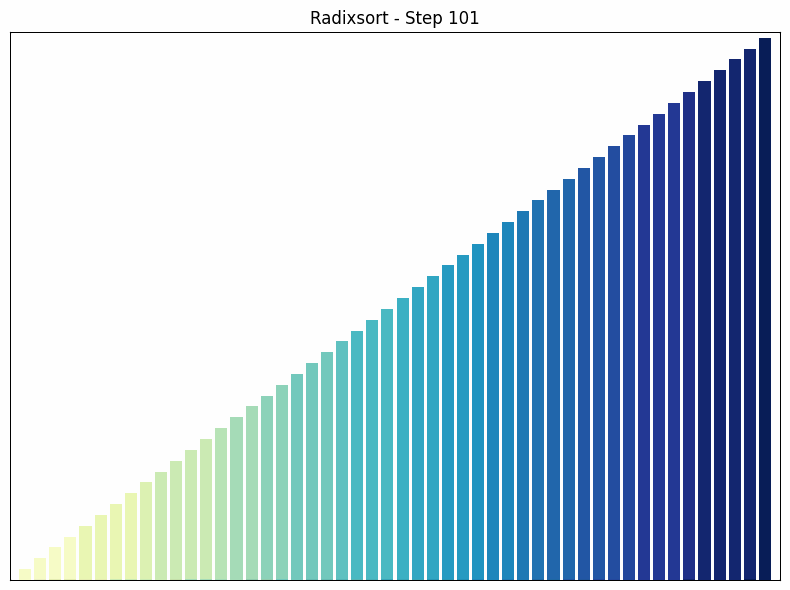 Radixsort Sortiervorgang
Radixsort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
n = 50
dataset = random.sample(range(1, n+1), n)def flatten_and_fill(buckets, arr_length):
"""
Flacht eine Liste von Listen (Buckets) ab und füllt die resultierende Liste mit Nullen auf, bis sie die
angegebene Länge erreicht. Diese Funktion wird in Sortieralgorithmen verwendet, die Buckets verwenden,
um Elemente zu sortieren, wie z.B. der Radix-Sort-Algorithmus.
Args:
buckets (list): Eine Liste von Listen, die abgeflacht werden soll.
arr_length (int): Die gewünschte Länge der resultierenden Liste.
Returns:
list: Eine abgeflachte Liste, die mit Nullen aufgefüllt ist, bis sie die angegebene Länge erreicht.
"""
flattened = [item for sublist in buckets for item in sublist]
return flattened + [0] * (arr_length - len(flattened))
def radix_sort(arr):
"""
Implementiert den Radix-Sort-Algorithmus. Dieser Algorithmus sortiert eine Liste von Zahlen, indem er sie
basierend auf den einzelnen Ziffern von links nach rechts sortiert. Der Algorithmus verwendet eine
Bucket-Sort-Strategie, um die Zahlen in "Eimer" zu sortieren, basierend auf der aktuellen Ziffer, die
sortiert wird.
Args:
arr (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
snapshots (list): Eine Liste von Listen, die den Zustand der sortierten Liste nach jedem Schritt enthält.
"""
max_value = max(arr)
exp = 1
snapshots = [arr.copy()] # Initialer Zustand
while max_value // exp > 0:
buckets = [[] for _ in range(10)]
for num in arr:
digit = (num // exp) % 10
buckets[digit].append(num)
snapshots.append(flatten_and_fill(buckets, len(arr))) # Save the snapshot
arr = [num for bucket in buckets for num in bucket]
exp *= 10
return snapshotsfor i, data in enumerate(radix_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/radix_sort", name="Radixsort")Bogo Sort
Bogo Sort ist ein ineffizienter und nicht-deterministischer Sortieralgorithmus. Er funktioniert, indem er das Array zufällig mischt und dann überprüft, ob es sortiert ist. Dieser Vorgang wird wiederholt, bis das Array zufällig in die richtige Reihenfolge gebracht wird. Aus diesem Grund habe ich die größe des Datensatzes verkleinert.
- Funktionsweise: Bogo Sort mischt das Array zufällig und überprüft dann, ob es sortiert ist. Dieser Prozess wird so lange wiederholt, bis das Array zufällig in die richtige Reihenfolge gebracht wird. Es gibt keine Garantie dafür, wie lange dies dauern wird. Im schlimmsten Fall kann es unendlich lange dauern.
- Zeitkomplexität: Die Zeitkomplexität von Bogo Sort ist im Durchschnitt und im schlimmsten Fall unendlich, da es keine Garantie dafür gibt, dass der Algorithmus jemals endet. Dies macht Bogo Sort extrem ineffizient.
- Besonderheiten: Bogo Sort ist ein Beispiel für einen extrem ineffizienten und unpraktischen Sortieralgorithmus. Er wird oft als humorvolles Beispiel für einen schlechten Algorithmus verwendet.
 Bogosort Sortiervorgang
Bogosort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
n = 5 # Reduzierte Größe des Datensatzes
dataset = random.sample(range(1, n+1), n)def bogo_sort(data):
"""
Implementiert den Bogo-Sort-Algorithmus. Dieser Algorithmus sortiert eine Liste durch wiederholtes zufälliges
Mischen der Elemente, bis die Liste sortiert ist. Es ist ein sehr ineffizienter Sortieralgorithmus mit einer
durchschnittlichen Zeitkomplexität von O((n+1)!), wobei n die Anzahl der Elemente in der Liste ist.
Args:
data (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
steps (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Schritt enthält.
"""
steps = [] # Initialisiere eine Liste, um die Schritte des Sortierprozesses zu speichern
# Wiederhole den Prozess, bis das Array sortiert ist
while not all(data[i] <= data[i+1] for i in range(len(data)-1)):
steps.append(list(data)) # Füge den aktuellen Zustand des Arrays zu den Schritten hinzu
random.shuffle(data) # Mische das Array zufällig
steps.append(list(data)) # Füge das endgültig sortierte Array zu den Schritten hinzu
return steps # Gebe die Liste der Schritte zurückfor i, data in enumerate(bogo_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/bogo_sort", name="Bogosort")Sleep Sort
Sleep Sort ist ein unkonventioneller und ineffizienter Sortieralgorithmus, der auf der Idee basiert, dass jeder Thread für eine Zeit “schläft”, die proportional zum Wert des Elements ist. Auch hier verzichte darauf, einen großen Datensatz zu verwenden.
- Funktionsweise: Sleep Sort startet für jedes Element im Array einen Thread. Jeder Thread “schläft” für eine Zeit, die proportional zum Wert des Elements ist. Wenn ein Thread aufwacht, gibt er sein Element aus. Da Threads mit kleineren Werten zuerst aufwachen, werden die Elemente in sortierter Reihenfolge ausgegeben.
- Zeitkomplexität: Die Zeitkomplexität von Sleep Sort ist , wobei das größte Element im Array ist. Dies macht Sleep Sort ineffizient für große Datenmengen oder Arrays mit sehr großen Werten.
- Besonderheiten: Sleep Sort ist nicht deterministisch, da die Reihenfolge der Ausgabe bei gleichen Elementen variieren kann. Es ist eher eine Kuriosität und nicht für den praktischen Einsatz gedacht.
 Sleepsort Sortiervorgang
Sleepsort Sortiervorgang
# Erzeuge einen zufälligen Datensatz
n = 50
dataset = random.sample(range(1, n+1), n)import time
import threading
def sleep_sort(data):
"""
Sortiert eine Liste von Zahlen mit dem Sleep-Sort-Algorithmus. Dieser Algorithmus verwendet Multithreading,
um die Zahlen zu sortieren. Jede Zahl in der Liste wird einem separaten Thread zugewiesen. Jeder Thread
wartet eine Zeit proportional zum Wert der Zahl, bevor er die Zahl in die sortierte Liste einfügt.
Args:
data (list): Die Liste von Zahlen, die sortiert werden soll.
Returns:
all_steps (list): Eine Liste, die den Zustand der sortierten Liste nach jedem Schritt enthält.
"""
sorted_data = [0] * len(data) # Initialisiere sorted_data mit Nullen
all_steps = [] # Initialisiere die Liste, um alle Schritte zu speichern
index = 0 # Initialisiere den Index
def sleep_func(x):
nonlocal index # Deklariere index als nonlocal
time.sleep(x/10) # Lasse den Thread für eine Zeit proportional zum Wert von x schlafen
sorted_data[index] = x # Füge das Element am aktuellen Index ein
index += 1 # Erhöhe den Index
all_steps.append(list(sorted_data)) # Füge den aktuellen Zustand von sorted_data zu all_steps hinzu
threads = []
for num in data:
t = threading.Thread(target=sleep_func, args=(num,)) # Erstelle einen Thread für jede Zahl im Array
threads.append(t)
t.start() # Starte den Thread
for t in threads:
t.join() # Warte, bis alle Threads beendet sind
return all_steps # Gebe die Liste aller Schritte zurückfor i, data in enumerate(sleep_sort(dataset)):
update_chart(data, i+1, xlim=[0, n+1], ylim=[0, n+.5], folder_name="Sortieralgorithmen/sleep_sort", name="Sleepsort")Es gibt noch viele weitere Sortieralgorithmen. Und den einen oder anderen werde ich vielleicht noch ergänzen.
Gifs erstellen
In den folgenden Zeilen findet sich der Code, mit dem ich dem die Gifs erstellt habe. Natürlich lässt sich vieles sicher eleganter und schlanker programmieren, aber ich halte es so noch für leserlich.
def get_subfolders(folder_path):
"""
Retrieves the subfolders in the specified folder.
Parameters:
folder_path (str): The path to the folder from which to retrieve the subfolders.
Returns:
list: A list of paths to the subfolders in the specified folder.
"""
return [f.path for f in os.scandir(folder_path) if f.is_dir()]def get_images(subfolder, max_image_width, max_image_height):
"""
Retrieves and resizes images from a specified subfolder.
Parameters:
subfolder (str): The path to the subfolder containing the images.
max_image_width (int): The maximum width to which the images will be resized.
max_image_height (int): The maximum height to which the images will be resized.
Returns:
list: A list of numpy arrays representing the resized images.
"""
png_files = sorted(glob.glob(os.path.join(subfolder, '*.png')))
return [np.array(Image.fromarray(imageio.imread(png_file)[..., :3]).resize((max_image_width, max_image_height))) for png_file in png_files]def create_final_gif_image(i, gif_images, num_gifs_down, num_gifs_across, max_image_height, max_image_width):
"""
Creates a single frame for the final GIF.
Parameters:
i (int): The index of the current frame.
gif_images (list): A list of lists containing the images for each GIF.
num_gifs_down (int): The number of GIFs to be arranged vertically in the final GIF.
num_gifs_across (int): The number of GIFs to be arranged horizontally in the final GIF.
max_image_height (int): The maximum height of the images to be included in the GIF.
max_image_width (int): The maximum width of the images to be included in the GIF.
Returns:
final_gif_image (numpy.ndarray): A 3D numpy array representing the final GIF image for the current frame.
"""
final_gif_image = np.zeros((max_image_height * num_gifs_down, max_image_width * num_gifs_across, 3), dtype=np.uint8)
for j in range(num_gifs_down):
for k in range(num_gifs_across):
images = gif_images[j * num_gifs_across + k]
if i < len(images):
final_gif_image[j * max_image_height:(j + 1) * max_image_height, k * max_image_width:(k + 1) * max_image_width] = images[i]
else:
final_gif_image[j * max_image_height:(j + 1) * max_image_height, k * max_image_width:(k + 1) * max_image_width] = images[-1]
return final_gif_imagedef create_final_gif(folder_path, num_gifs_across, num_gifs_down, max_image_width, max_image_height, output_file):
"""
Creates a final GIF from images in the subfolders of the given folder.
Parameters:
folder_path (str): The path to the folder containing the subfolders with images.
num_gifs_across (int): The number of GIFs to be arranged horizontally in the final GIF.
num_gifs_down (int): The number of GIFs to be arranged vertically in the final GIF.
max_image_width (int): The maximum width of the images to be included in the GIF.
max_image_height (int): The maximum height of the images to be included in the GIF.
output_file (str): The path to the output file where the final GIF will be saved.
Returns:
None
"""
subfolders = get_subfolders(folder_path)
gif_images = [get_images(subfolder, max_image_width, max_image_height) for subfolder in subfolders]
final_gif_images = [create_final_gif_image(i, gif_images, num_gifs_down, num_gifs_across, max_image_height, max_image_width) for i in range(max(len(images) for images in gif_images))]
imageio.mimsave(output_file, final_gif_images, duration=0.5)create_final_gif(
folder_path="Sortieralgorithmen",
num_gifs_across=3,
num_gifs_down=3,
max_image_width=200,
max_image_height=200,
output_file='final.gif')