Aus gegebenem Anlass habe ich mich mit dem Thema Job Scheduling bzw. im ersten Schritt einer Job Queue auseinandergesetzt. Hierbei handelt es sich um die Planung und Ausführung von Aufgaben, die zu einem bestimmten Zeitpunkt oder in regelmäßigen Abständen ausgeführt werden sollen. In diesem Beitrag möchte ich dir zeigen, wie ich diese Funktion mit Python realisiert habe. Im ersten Schrift handelt es sich um eine Warteschlage für eine definierte Anzahl von Threads. Darüber hinaus verwende ich eine einfache Streamlit-Oberfläche, um die geplanten Aufgaben zu verwalten.
Warum Job Scheduling/Queue?
Ich stand vor der Herausforderung, dass ich gerne eine Warteschlange für ein von mir eingesetztes Python Framework einsetzen wollte. Weil die Ausführung eines einzelnen Jobs teilweise bis zu mehrere Tage dauern kann und von mir durch eine Streamlit-Oberfläche auf einem Server getriggert wird, wollte ich das Ausführen und Abarbeiten der Jobs automatisieren. Dafür gibt es natürlich bereits fertige Pakete. Diese waren mir aber teilweise zu umfangreich oder brauchten z.B. weitere Software-Installationen, die ich auf dem Server nicht durchführen kann/darf.
Nicht zuletzt macht es aber auch Spaß, sich so etwas selbst anzunehmen.
Der Code
In den folgenden Abschnitten zeige ich den Code, den ich verwendet habe um meine Variante eines Job-Schedulers in Kombination mit Streamlit zu erstellen. Ich versuche auf Details einzugehen und die wichtigsten Punkte zu erklären.
Es wird Dateien geben:
countdown.py: In dieser Datei versteckt sich der auszuführende Job.queue_processor.py: Enthält die Funktionen, die zum Organisieren der Warteschlange benötigt werden.job_queue.txt: Hier werden die Jobs samt Status und UUID sowie Parametern gelistet.queue_test_streamlit.py: Hier wird die Streamlit-Oberfläche oder -App erstellt.#
Der auszuführende Job countdown.py
Kommen wir zunächst zu dem Job, der ausgeführt werden soll. Hierbei handelt es sich um einen simplen Countdown, um den Scheduler schnell und einfach testen zu können. Der Job wird aus queue_processor.py heraus aufgerufen. Im Aufruf ist auch ein Parameter, die Zeit, die der Countdown herunter zählen soll, enthalten.
import sys
import time
def countdown(seconds):
for i in range(seconds, 0, -1):
print(f"Countdown: {i} seconds")
time.sleep(1)
def main():
if len(sys.argv) < 2:
print("Error: Missing parameter")
sys.exit(1)
try:
seconds = int(sys.argv[1])
countdown(seconds)
except ValueError:
print("Error: Invalid parameter")
sys.exit(1)
if __name__ == "__main__":
main()Die Ausgabe kann dann beispielsweise so aussehen:
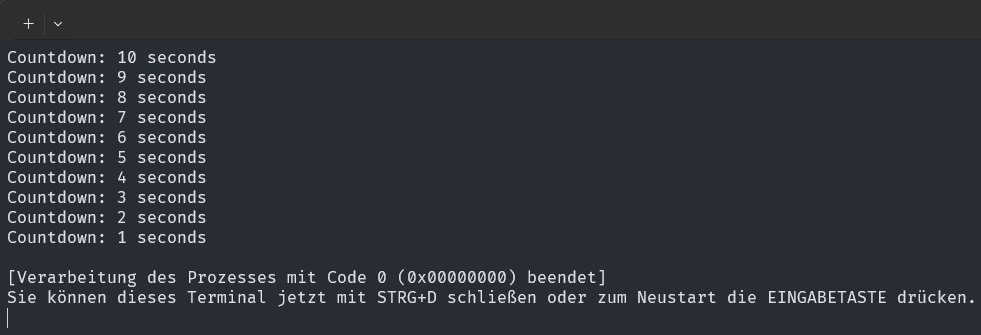 Output eines einzelnen Jobs
Output eines einzelnen Jobs
Der Processor queue_processor.py
In dieser Datei sind alle Funktionen enthalten, die für die Organisation der Jobs benötigt werden. Ich werde im folgenden die Funktionen einzeln beschreiben.
Imports
Zunächst müssen ein paar Imports getätigt werden. Außerdem setzen wir die Anzahl maximaler, synchroner Jobs und ein paar Pfade.
import threading
import subprocess
import uuid
import os
# Maximale Anzahl gleichzeitiger Jobs
MAX_CONCURRENT_JOBS = 3
# Globale Variable zur Verfolgung der aktiven Threads
active_threads = 0
lock = threading.Lock()
current_path = os.getcwd()
JOBS_FILE = os.path.join(current_path, "Simple_Example", "job_queue.txt")Einen Job zur Warteschlange hinzufügen: add_job_to_queue(job_path, parameter)
Fügt einen neuen Job zur Warteschlange hinzu, indem eine eindeutige Job-ID (UUID) generiert und in die Datei job_queue.txt geschrieben wird. Der Job wird dann zur Warteschlange job_queue hinzugefügt (job_queue.put((job_id, job_path, parameter))).
def add_job_to_queue(job_path, parameter):
job_id = str(uuid.uuid4())
with lock:
with open(JOBS_FILE, "a") as file:
file.write(f"{job_id} {job_path} {parameter} PENDING\n")
process_jobs()
return job_idWas ist eine UUID?
Eine UUID (Universally Unique Identifier) ist ein 128-Bit-Wert, der verwendet wird, um Informationen in verteilten Systemen eindeutig zu identifizieren. Sie besteht aus 32 hexadezimalen Zeichen, die in fünf Gruppen unterteilt sind und durch Bindestriche getrennt werden (z.B. 123e4567-e89b-12d3-a456-426614174000). UUIDs sind nahezu garantiert einzigartig, da sie auf einer Kombination von Faktoren wie Zeit, Raum (z.B. MAC-Adresse) und zufälligen oder pseudozufälligen Zahlen basieren. Dies macht sie ideal für die eindeutige Identifizierung von Objekten in verteilten Systemen, ohne dass eine zentrale Koordination erforderlich ist.
UUIDs gibt es in verschiedenen Versionen:
- Version 1: Basierend auf Zeit und MAC-Adresse.
- Version 2: Basierend auf Zeit, MAC-Adresse und POSIX UID/GID.
- Version 3: Basierend auf MD5-Hash eines Namespaces und Namens.
- Version 4: Basierend auf zufälligen Zahlen.
- Version 5: Basierend auf SHA-1-Hash eines Namespaces und Namens.
Version 4 wird am häufigsten verwendet, da sie zufällig generiert wird und eine hohe Einzigartigkeit bietet.
Den Status eines Jobs aktualisieren: update_job_status(job_id, status)
Aktualisiert den Status eines Jobs in der Datei job_queue.txt. Die Funktion verwendet einen Lock, um sicherzustellen, dass die Datei sicher aktualisiert wird. Die Funktion wird durch die ‘execute_job()‘-Funktion aufgerufen.
def update_job_status(job_id, status):
with lock:
jobs = load_jobs()
with open(JOBS_FILE, "w") as file:
for job in jobs:
if job[0] == job_id:
file.write(" ".join(job[:-1] + (status,)) + "\n")
else:
file.write(" ".join(job) + "\n")Was ist oder macht der lock?
Der lock sorgt dafür, dass immer nur ein Thread gleichzeitig auf die Datei zugreifen kann. Dies verhindert, dass mehrere Threads gleichzeitig Änderungen vornehmen und die Datei beschädigen.
Job ausführen: execute_job(job_id, job_path, parameter)
Führt einen Job aus, indem ein neuer Prozess gestartet wird, der das angegebene Skript mit den angegebenen Parametern ausführt. Der Status des Jobs wird vor und nach der Ausführung aktualisiert.
def execute_job(job_id, job_path, parameter):
global active_threads
update_job_status(job_id, "RUNNING")
process = subprocess.Popen(
["cmd", "/C", "python", job_path, parameter],
creationflags=subprocess.CREATE_NEW_CONSOLE)
process.wait()
update_job_status(job_id, "COMPLETED")
with lock:
active_threads -= 1
process_jobs()Die Zeile subprocess.Popen startet einen neuen Prozess, der das angegebene Python-Skript (job_path, also countdown.py) mit dem angegebenen Parameter (parameter) ausführt.
["cmd", "/C", "python", job_path, parameter]: Dies ist die Befehlszeile, die ausgeführt wird.cmd /Cstartet die Windows-Eingabeaufforderung und führt den folgenden Befehl aus (python job_path parameterbzwpython countdown.py 10).creationflags=subprocess.CREATE_NEW_CONSOLE: Dieses Flag erstellt bzw. öffnet eine neue Konsole für den gestarteten Prozess.
Die Zeile process.wait() wartet darauf, dass der gestartete Prozess beendet wird, bevor der Code fortfährt. Dies stellt sicher, dass der Job vollständig abgeschlossen ist, bevor der Status auf COMPLETED aktualisiert wird.
Job aus der Warteschlange entfernen mit remove_job_from_queue(job_id)
Entfernt einen Job aus der Datei job_queue.txt, indem alle Zeilen außer derjenigen mit der angegebenen Job-ID/UUID beibehalten werden. Die Funktion verwendet auch wieder einen Lock für die sichere Dateioperation.
def remove_job_from_queue(job_id):
with lock:
with open(JOBS_FILE, "r+") as file:
lines = file.readlines()
file.seek(0)
file.truncate()
for line in lines:
parts = line.strip().split()
if parts[0] != job_id:
file.write(line)Alle Jobs anzeigen mit get_all_jobs()
Liest alle Jobs aus der Datei job_queue.txt und gibt eine Liste von Dictionaries zurück, die die Job-ID, den Job-Pfad, die Parameter und den Status jedes Jobs enthalten.
def get_all_jobs():
with lock:
return load_jobs()def load_jobs():
jobs = []
with open(JOBS_FILE, "r") as file:
for line in file:
parts = line.strip().split()
jobs.append((parts[0], parts[1], parts[2], parts[3]))
return jobsAusführen eines Jobs mit process_jobs()
Überwacht die Warteschlange job_queue und führt Jobs aus, sobald sie verfügbar sind. Die Funktion läuft in einer Endlosschleife und verwendet einen Lock, um die Warteschlange sicher zu verwalten.
def process_jobs():
global active_threads
with lock:
jobs = load_jobs()
for job in jobs:
if job[3] == "PENDING" and active_threads < MAX_CONCURRENT_JOBS:
job_id, job_path, parameter, _ = job
active_threads += 1
threading.Thread(target=execute_job, args=(job_id, job_path, parameter)).start()
breakStarten des Job-Verarbeitungsthreads
Startet einen neuen Thread, der die Funktion process_jobs ausführt. Der Thread läuft im Hintergrund und verarbeitet kontinuierlich Jobs aus der Warteschlange.
threading.Thread(target=process_jobs, daemon=True).start()Die Warteschlange job_queue.txt
In dieser Text-Datei werden die Jobs mit ihren UUIDs, dem Parameter und dem jeweiligen Status gespeichert. Diese Datei wird unter Anderem genutzt, um sich neue Jobs zu holen und erledigte als solches zu markieren.
6f640ce6-5a3a-4161-8135-fc62bd573897 countdown.py 25 COMPLETED
694d73e2-0d5f-4090-8518-d241c94aaf6b countdown.py 25 COMPLETED
62e82184-8b7c-406a-83df-31dd327088b3 countdown.py 5 COMPLETED
32155a26-4b29-492f-b6ea-5123191aae63 countdown.py 5 COMPLETED
fd6b28ed-65c4-4a79-b9bb-84cfbc2d0c28 countdown.py 5 COMPLETED
93550566-238a-4b0c-9cb2-9c42f80123fa countdown.py 5 COMPLETED
6743c4ce-cbdb-4aff-861c-4b380e825688 countdown.py 5 COMPLETED
0ac2be3a-1f72-4f11-a2c9-52b7eb2b7d69 countdown.py 5 COMPLETED
f016a61c-e936-4c88-9c08-89e9f1a51fe2 countdown.py 5 COMPLETED
6d8f1e81-7964-4791-9901-f2057bc1db4d countdown.py 5 COMPLETED
82499fd2-233e-48d3-b620-aecf50d78498 countdown.py 5 COMPLETED
cc057b2d-f471-4b19-b11b-c5be9d2fd8ac countdown.py 10 RUNNING
e9d4620b-5ba5-4bd4-81e4-4a20e11c88e2 countdown.py 5 PENDINGManuelle Änderungen werden hier vermutlich nicht vorgenommen.
Die Streamlit-App queue_test_streamlit.py
Die folgende Streamlit-App bietet eine Benutzeroberfläche zur Verwaltung der Job-Warteschlange. Benutzer können Jobs hinzufügen, die Warteschlange aktualisieren und Jobs aus der Warteschlange entfernen. Die App ist wirklich keine Besonderheit, erfüllt aber seinen Job.
Die besagten Funktionen werden aus dem queue_processor importiert.
import streamlit as st
import pandas as pd
from queue_processor import add_job_to_queue, get_all_jobs, remove_job_from_queue
def main():
st.title("Python Job Queue")
job_path = st.text_input("Job Path", value="Simple_Example/countdown.py")
parameter = st.text_input("Parameter", value="10")
if st.button("Add Job"):
job_id = add_job_to_queue(job_path, parameter)
st.success(f"Job {job_id} added to queue")
if st.button("Refresh Job Queue"):
jobs = get_all_jobs()
df = pd.DataFrame(jobs)
st.table(df)
job_id = st.text_input("Job UUID")
if st.button("Remove Job from queue"):
remove_job_from_queue(job_id)
st.success(f"Job {job_id} removed from queue")
if __name__ == "__main__":
# Führe die Streamlit-App aus
main()Es gibt zwei Eingabefelder.
- In
job_pathdefiniert man den Pfad zur auszuführenden Datei, wie in diesem Beispiel zucountdown.py. Parameterist ein Argument, dass man dem Job übergibt. Ob ein Argument notwendig ist, hängt ganz vom Anwendungsfall und Job ab. In diesem Beispiel übergibt man die Wartezeit (in Sekunden).
Dann folgen zwei Buttons:
- Mit dem
Add JobButton wird der zuvor genannte Job der Warteschlange hinzugefügt. - Der
Refresh Job QueueButton sorgt für eine Aktualisierung und Darstellung, der in der Warteschlange gelisteten Jobs.
Nun folgt ein weiteres Eingabefeld. In Job UUID kann man in dieser App die UUID eines abzubrechenden Jobs eingeben. Bestätigt man die Eingabe durch den Remove Job from queue Button, wird der Job aus der Warteschlange gelöscht.
Ausführen des Beispiels
In diesem Abschnitt geht es nun darum, den Job-Scheduler zu testen. Zunächst muss natürlich eine Entwicklungsumgebung mit den entsprechenden Abhängigkeiten eingerichtet werden.
Installieren der Abhängigkeiten
Eine ausführlichere Beschreibung zu diesem Thema findest du hier. Im folgenden nur stichpunktartig:
-
Zunächst in den Ordner mit dem Projekt navigieren (z.B. innerhalb der Kommandozeile)
-
Erstellen der Umgebung mit
python -m venv .venvC:\***\Python_Project>python -m venv .venvSo wird die Entwicklungsumgebung im Ordner :file_folder:
.venverstellt. -
Mit dem Befehl
activatein einem der Unterordner aktiviert man die Umgebung und kann z.B. Pakete installieren.C:\***\Python_Project>venv\Scripts\activate -
Wir benötigen nur weitere Pakete,
pandasundstreamlit.(.venv) C:\***\Python_Project>pip install pandas streamlitAlle weiteren Pakete sollten mit deiner Python-Installation gekommen sein.
Starten der Streamlit-App
Wir befinden uns nun bereits im Projekt Ordner und haben alle Pakete installiert und Dateien erstellt und mit Code gefüllt. Als nächstes starte ich die Streamlit-Oberfläche.
(.venv) C:\***\Python_Project>streamlit run queue_test_streamlit.pyWir bekommen folgende Ausgabe:
(.venv) C:\***\Python_Project>streamlit run queue_test_streamlit.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://123.123.123:8501Gleichzeitig sollte sich der Browser öffnen und die oben genannte URL, bestehend aus IP oder Localhost und Port, IP aufrufen. Falls das nicht geschieht, kann man die URL auch manuell aufrufen.
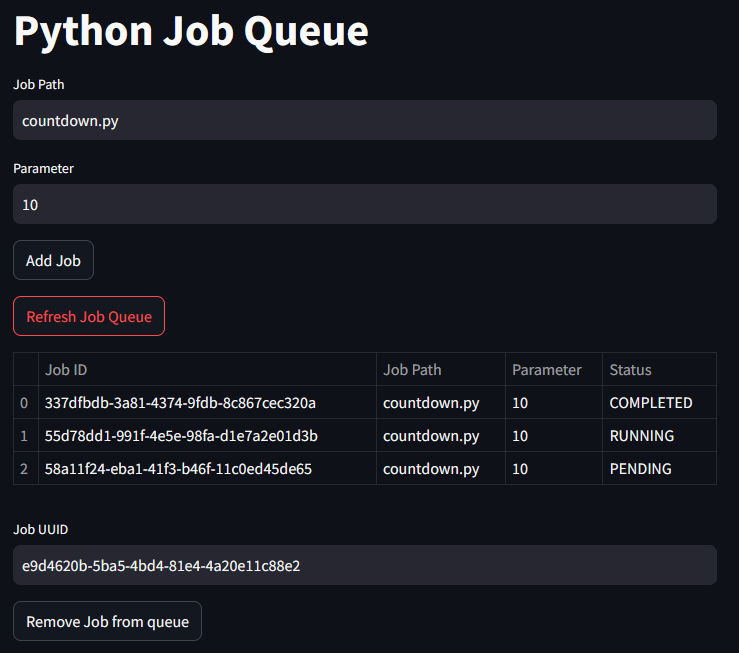 Streamlit Oberfläche
Streamlit Oberfläche
Und hier kann man nun fleißig die einzelnen Funktionen testen.
Zusammenfassung
In den obigen Abschnitten haben wir einen einfachen Job-Scheduler in Python erstellt. Dieser Scheduler wird mit Hilfe, aber nicht ausschließlich durch, Streamlit befüllt und organisiert. Man kann Jobs hinzufügen, löschen oder sich die Warteschlange anzeigen lassen. Die Streamlit-Oberfläche bietet hier eine einfache Möglichkeit mit dem Scheduler zu interagieren. Grundsätzlich kann man die Befehle aber auch anders aufrufen.