Herkömmliche Neuronale Netze (NNs) sind zwar leistungsfähig, stoßen aber bei komplexen physikalischen Systemen auch mal an ihre Grenzen. Sie integrieren oft kein physikalisches Vorwissen, was zu inkonsistenten oder intransparenten Vorhersagen führen kann. Schließlich handelt es sich immer noch um Black-Boxes.
Eine Möglichkeit, dieses Problem zu adressieren, sind Physik-Informierte Neuronale Netze (PINNs). Sie integrieren grundlegende physikalische Prinzipien und Gesetze (oft Differentialgleichungen) in ihrem Lernprozess.
Man kombiniert sozusagen die Flexibililität von Neuronalen Netzen mit physikalischen Gesetzen.
Was sind PINNs?
PINNs lernen, indem die physikalischen Gesetze in ihrer Verlustfunktion eingebettet werden. Das Neuronale Netz minimiert nicht nur den Fehler zu den Beobachtungsdaten, sondern wird zusätzlich bestraft, wenn die Vorhersagen des neuronalen Netzes physikalische Gesetze verletzen.
Ein kleines Beispiel: In einem geschlossenen, einfachen System erhöht sich die Temperatur, also sollte auch der Druck steigen. Tut er das nicht, scheint die Vorhersage das physikalische Gesetz zu verletzen. Diese Verletzung wird im Trainingsprozess in der Loss-Funktion berücksichtigt.
Was PINNs erst praktikabel macht, ist die Automatische Differenzierung (AD). Viele physikalische Gesetze sind Differentialgleichungen - sie enthalten Ableitungen wie Geschwindigkeit (erste Ableitung der Position) oder Beschleunigung (zweite Ableitung).
Zuvor war es oft extrem aufwendig, diese Ableitungen manuell zu berechnen. Mit AD können moderne Deep Learning Frameworks wie TensorFlow oder PyTorch diese Ableitungen automatisch und exakt berechnen. Das neuronale Netz lernt beispielsweise eine Position x(t), und AD berechnet automatisch dx/dt (Geschwindigkeit) und d2x/dt2 (Beschleunigung) - genau das, was für physikalische Gleichungen benötigt wird.
Physikalische Gesetze dienen außerdem als “Constraint”, der das Lernen und den Trainingsprozess zu physikalisch konsistenten Lösungen lenkt. Das führt letztlich zu effizienterem, robusterem Lernen und besserer Generalisierungsfähigkeit auf ungesehene Szenarien.
Das führt auch dazu, dass ein PINN mit kleineren, spärlichen, unvollständigen Datensätzen trainiert werden kann, weil die Physik starkes Vorwissen liefert, während traditionelle NNs oft riesige Mengen hochwertiger Daten benötigen.
Der entscheidende Unterschied zu herkömmlichen NNs: Traditionelle neuronale Netze sind “Black Boxes” - sie liefern Ergebnisse, aber niemand kann erklären, wie sie zu diesen Vorhersagen kommen. PINNs hingegen sind ein Stück weit transparent: Ihre Vorhersagen müssen zwangsläufig den physikalischen Gesetzen folgen, die wir explizit in das Training eingebaut haben. Das macht sie nicht nur interpretierbarer, sondern auch deutlich vertrauenswürdiger für kritische Anwendungen.
graph TD
subgraph "Traditionelles NN"
A[Trainingsdaten] --> B[Neuronales Netz] --> C[Vorhersagen]
D[❌ Nur datenbasiert<br/>❌ Keine Physik<br/>❌ Black Box]
end
subgraph "Physics-Informed NN (PINN)"
E[Trainingsdaten] --> F[Neuronales Netz]
G[Physikalische Gesetze<br/>Differentialgleichungen] --> F
F --> H[Vorhersagen]
I[✅ Daten + Physik<br/>✅ Physikalisch konsistent<br/>✅ Interpretierbar]
end
J[Wenige/spärliche Daten] --> A
J --> E
classDef traditional fill:#ffebee,stroke:#f44336
classDef pinn fill:#e8f5e8,stroke:#4caf50
classDef data fill:#e3f2fd,stroke:#2196f3
classDef physics fill:#fff3e0,stroke:#ff9800
class A,B,C,D traditional
class E,F,H,I pinn
class J data
class G physics
Vorteile von PINNs gegenüber Standard-NNs
PINNs bieten einige Vorteile gegenüber traditionellen neuronalen Netzen.
Zum einen wäre da die verbesserte Genauigkeit und Interpretierbarkeit. Sie liefern genauere und zuverlässigere Vorhersagen, insbesondere bei komplexen, nichtlinearen Systemen, wie beispielsweise bei der Beschreibung von Turbulenzen. Die Ergebnisse sind physikalisch plausibel, was natürlich für die Sicherheit und Zuverlässigkeit wichtig und entscheidend ist.
Ein weiterer Punkt ist die Dateneffizienz und Robustheit. PINNs reduzieren den Bedarf an großen, sauberen Datensätzen und können effektiv aus spärlichen oder verrauschten Daten lernen.
Auch die Geschwindigkeit, Skalierbarkeit und Effizienz sind nicht zu vernachlässigen. Nach dem Training liefern PINNs sehr schnelle Ergebnisse für Echtzeit-Inferenzen und Optimierungsprobleme. Außerdem reduzieren sie die Rechenlast im Vergleich zu rein numerischen Methoden.
PINNs sind auch exzellent bei inversen Problemen. Das Ziel ist es, unbekannte Parameter, Bedingungen oder Ursachen aus beobachteten Daten abzuleiten, beispielsweise Materialeigenschaften oder Randbedingungen. Das unterscheidet sie von Vorwärtsproblemen, bei denen es um die Vorhersage von Ergebnissen geht.
Aber PINNs können noch mehr als nur Probleme lösen. Sie können partielle Differentialgleichungen datengesteuert entdecken und sogar die zugrundeliegenden mathematischen Ausdrücke eines Systems durch symbolische Regression aufdecken. Damit wird KI zu einem echten Werkzeug für wissenschaftliche Entdeckungen, technische Designoptimierung und präzise Ursachenanalyse.
Genug Theorie, kommen wir zum praktischen Beispiel.
Praktisches Beispiel: Feder-Masse-Dämpfer-System
Um die Funktionsweise eines PINN zu veranschaulichen, betrachten wir die Modellierung eines Feder-Masse-Dämpfer-Systems. Dieses System wird durch eine gewöhnliche Differentialgleichung (ODE) beschrieben, welche die Bewegung einer Masse unter Federkraft und Dämpfung darstellt:
m⋅dt2d2x+c⋅dtdx+k⋅x=0
Unser PINN wird lernen, die Auslenkung x(t) über die Zeit t zu approximieren, indem es diese ODE direkt in seine Verlustfunktion integriert.
Die PINN-Verlustfunktion
Im Gegensatz zu traditionellen neuronalen Netzen ist die Verlustfunktion eines Physik-informierten neuronalen Netzes etwas komplexer aufgebaut. Sie besteht in unserem Beispiel im Wesentlichen aus drei Teilen:
Physik-Verlust: Dieser Teil misst, wie gut das Modell die zugrunde liegende Differentialgleichung (ODE) an den Kollokationspunkten erfüllt.
Positions-Daten-Verlust: Hier wird geprüft, wie gut das Modell mit den bekannten Positionsdaten übereinstimmt.
Geschwindigkeits-Daten-Verlust: Dieser Term vergleicht die vom Modell berechnete Geschwindigkeit mit den tatsächlich vorhandenen Daten.
Zu den Gewichten später mehr. An dieser Stelle ist wichtig zu verstehen, dass es diese besonderen Verlustfunktion gibt.
Umsetzung
Wir beginnen wieder mit den Imports, die sich dieses Mal wirklich in Grenzen halten.
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as pltfrom typing import Dict, Any, Tuple
Und dann definieren ich die System-Parameter.
class SystemParameters: def __init__(self, m: float = 1.0, c: float = 0.5, k: float = 10.0): self.mass = m # Masse self.damping = c # Dämpfungskoeffizient self.stiffness = k # Federkonstante
DataOnlyModel
Es folgt die DataOnlyModel Klasse. Sie repräsentiert einen rein datenbasierten Ansatz zur Modellierung physikalischer Systeme. Sie dient als direkter Vergleichspartner zum PINN und zeigt, was passiert, wenn man versucht, komplexe Dynamiken ausschließlich aus wenigen Datenpunkten zu lernen.
Das Modell verwendet dieselbe neuronale Netzwerkarchitektur wie das noch folgende PINN: Zwei Dense-Layer mit jeweils 64 Neuronen und tanh-Aktivierung, gefolgt von einem linearen Output-Layer. Diese bewusste Übereinstimmung eliminiert Architektur-bedingte Unterschiede und stellt sicher, dass etwaige Leistungsunterschiede ausschließlich auf den Lernansatz zurückzuführen sind.
Das Netz nimmt einen Zeitpunkt t als Input und soll die Position x(t) vorhersagen - genau wie das PINN.
Der entscheidende Unterschied zum PINN liegt in der Verlustfunktion. Das DataOnlyModel kennt keine physikalischen Gesetze und lernt ausschließlich aus den verfügbaren Datenpunkten:
Positionsdaten-Verlust: Standard Mean Squared Error zwischen vorhergesagter und tatsächlicher Position
Geschwindigkeitsdaten-Verlust: Hier wird es interessant - das Modell berechnet die Ableitung seines Outputs mittels tf.GradientTape und vergleicht diese mit den gegebenen Geschwindigkeitsdaten
Das DataOnlyModel hat keine Ahnung davon, dass seine Vorhersagen die Feder-Masse-Dämpfer-Gleichung m⋅dt2d2x+c⋅dtdx+k⋅x=0 erfüllen müssen. Es kennt nur die wenigen gegebenen Datenpunkte und versucht, daraus eine Funktion zu interpolieren.
@tf.function - Performance-Optimierung
Die @tf.function-Decorators in unseren Verlustfunktionen sind wichtig für die Performance. Dieser Decorator wandelt Python-Funktionen in optimierte TensorFlow-Graphen um.
Ohne @tf.function würde jede einzelne Operation in Python interpretiert, was langsam und ineffizient wäre. Mit @tf.function hingegen kompiliert TensorFlow die Funktion beim ersten Aufruf in einen statischen Berechnungsgraphen und optimiert ihn. Alle folgenden Aufrufe sind dann deutlich schneller.
Das ist für unser DataOnlyModel besonders wichtig, weil die data_loss_velocity-Funktion Ableitungen mit tf.GradientTape berechnet. Das ist rechenintensiv, und diese Funktionen werden in jedem einzelnen Trainingsschritt aufgerufen, also tausende Male. Die Graph-Optimierung beschleunigt die Gradienten-Berechnungen dann erheblich.
In der Praxis bedeutet das: Der erste Trainingsschritt ist etwas langsamer, weil TensorFlow die Funktion erst kompilieren muss. Aber alle folgenden Schritte laufen dann deutlich schneller. Und bei 5000 Epochen macht das einen enormen Unterschied!
Ich kann schon verraten, dass der Performance-Gewinn beim späteren PINN sogar noch dramatischer ist, weil wir dort noch komplexere, verschachtelte Gradient-Berechnungen für die zweiten Ableitungen haben.
tf.GradientTape - Automatische Ableitung
Das tf.GradientTape ist quasi TensorFlows Werkzeug für automatische Differenzierung (AD). Es zeichnet alle Operationen auf, während sie ausgeführt werden, und kann dann Ableitungen berechnen.
Du fragst dich jetzt vielleicht, warum unser DataOnlyModel das überhaupt braucht. Schauen wir uns dazu mal den Code an:
with tf.GradientTape() as tape: tape.watch(t_data_vel) # "Beobachte" die Zeitvariable x_pred = self(t_data_vel) # Berechne Positiondx_dt_pred = tape.gradient(x_pred, t_data_vel) # Ableite Geschwindigkeit
Der Grund ist folgender: Unser datenbasiertes Modell lernt ja nur die Position x(t). Wir haben aber auch Geschwindigkeitsdaten, die wir zum Trainieren nutzen wollen. Um jetzt die Geschwindigkeit aus der Position zu berechnen, brauchen wir die Ableitung dx/dt. Und genau das macht GradientTape für uns, es berechnet sie automatisch.
Ohne GradientTape müssten wir die Ableitung manuell approximieren, zum Beispiel durch finite Differenzen. Das wäre aber ungenau und ziemlich aufwendig. Mit GradientTape bekommen wir die exakte Ableitung automatisch, was natürlich perfekt für unseren Geschwindigkeits-Verlust ist.
Benutzerdefinierter Trainingsschritt (train_step)
Der Kern dieses Modells liegt in seiner benutzerdefinierten train_step-Implementierung, die es ihm ermöglicht, aus verschiedenen Arten von Überwachungsdaten zu lernen.
Der train_step erwartet ein Tupel von vier Eingabetensoren:
t_initial_pos, x_initial_pos: Zeitpunkte und zugehörige Positionen für die initiale Positionsinformation.
t_initial_vel, v_initial_vel: Zeitpunkte und zugehörige Geschwindigkeiten für die initiale Geschwindigkeitsinformation.
Die Gesamtverlustfunktion (total_loss) setzt sich aus zwei Komponenten zusammen, die beide als Mean Squared Error (MSE) berechnet werden:
Positionsdaten-Verlust (loss_data_pos): Hier wird der direkte Output des Modells (self(t_initial_pos)) mit den tatsächlichen (x_initial_pos) Positionswerten verglichen. Das ist ein Standard-Regressionsverlust.
Geschwindigkeitsdaten-Verlust (loss_data_vel): Das ist eigentlich der interessantere Teil. Um die Geschwindigkeit zu erhalten, wird die Ableitung des Modell-Outputs nach der Zeit (dxdt_at_t_initial_vel) berechnet. Das geschieht mit Hilfe von tf.GradientTape, wobei t_initial_vel explizit “gewatcht” wird, damit die Ableitung bezüglich dieses Inputs verfolgt werden kann. Der berechnete Gradient (also die Steigung der vom Modell gelernten Positionsfunktion) wird dann mit der tatsächlichen Geschwindigkeit (v_initial_vel) verglichen.
Nachdem der total_loss berechnet wurde, nutzt die tf.GradientTape die aufgezeichneten Operationen, um die Gradienten des Gesamtverlusts bezüglich aller trainierbaren Parameter des Netzwerks (self.trainable_variables) zu berechnen. Diese Gradienten werden dann vom Optimierer (self.optimizer.apply_gradients) verwendet, um die Gewichte des Netzwerks anzupassen und den Verlust zu minimieren.
Der train_step gibt dann ein Dictionary mit den einzelnen Verlustkomponenten und dem Gesamtverlust zurück, was für das Monitoring des Trainingsfortschritts nützlich ist.
Insgesamt ist dieses Modell ein rein datengesteuertes Modell, das versucht, eine unbekannte physikalische Beziehung (Position als Funktion der Zeit) zu lernen, indem es sowohl direkte Positionsmessungen als auch Informationen über die Rate der Positionsänderung (Geschwindigkeit) in seine Verlustfunktion integriert. Es unterscheidet sich von klassischen Physics-Informed Neural Networks (PINNs), da es keine explizite Differentialgleichung als physikalische Restriktion im Verlustterm verwendet, sondern lediglich die Ableitung des Outputs für den Geschwindigkeitsvergleich heranzieht.
Das neuronale Netz, das ich hier verwende, ist vom Aufbau her identisch mit meinem DataOnlyModel. Es besteht aus zwei Dense-Layern mit tanh-Aktivierung und einem einzelnen linearen Output-Layer. Auch hier soll das Netz die Position x als Funktion der Zeit t approximieren.
Im Gegensatz zum vorherigen Modell werden hier aber zusätzliche Systemparameter (mass, damping, stiffness) übergeben. Diese system_params sind feste Werte aus der realen Physik, die das System beschreiben, das wir modellieren wollen, ein Masse-Feder-Dämpfer-System.
Entscheidend für PINNs sind auch die bereits erwähnten pinn_weights. Diese Gewichtungen steuern, wie wichtig die verschiedenen Verlustanteile im Training sind. Zu
Benutzerdefinierter Trainingsschritt (train_step)
Der train_step ist hier etwas komplexer, weil er drei verschiedene Arten von “Fehlern” (oder Verlusten) berücksichtigt.
Da wäre zunächst der Daten-Input: Neben den bekannten Datenpunkten für die Startposition (t_initial_pos, x_initial_pos) und die Startgeschwindigkeit (t_initial_vel, v_initial_vel) kommt hier ein neuer Typ hinzu: die sogenannten Kollokationspunkte (t_collocation). Das sind Zeitpunkte, die wir zufällig wählen, um zu überprüfen, ob unser Modell die physikalischen Gesetze erfüllt.
Kollokationspunkte sind strategisch ausgewählte Punkte im Definitionsbereich der Differentialgleichung, an denen das neuronale Netz die physikalischen Gesetze erfüllen muss.
Im Gegensatz zu traditionellen numerischen Methoden, die auf einem festen Gitter arbeiten, können Kollokationspunkte flexibel verteilt werden. Sie ermöglichen es, die physikalischen Gesetze kontinuierlich im gesamten Definitionsbereich durchzusetzen. Je mehr Kollokationspunkte verwendet werden, desto strenger wird die physikalische Konsistenz überwacht.
Es gibt verschiedene Strategien für die Verteilung der Kollokationspunkte:
Gleichmäßige Verteilung: Das ist der einfachste Ansatz und funktioniert gut für glatte Lösungen.
Adaptive Verteilung: Hier werden mehr Punkte in Bereichen mit hoher Krümmung oder Gradienten gesetzt.
Zufällige Verteilung: Kann bei komplexen Geometrien vorteilhaft sein.
In unserem Feder-Masse-Dämpfer-Beispiel werden wir 200 gleichmäßig verteilte Kollokationspunkte über den Zeitbereich 0 bis 5 Sekunden verwenden. An jedem dieser Punkte muss das PINN die Gleichung m⋅dt2d2x+c⋅dtdx+k⋅x=0 erfüllen.
Dann gibt es noch die Ableitungen (tf.GradientTape(persistent=True)): persistent=True ermöglicht es, das gleiche Tape für mehrere Gradient-Berechnungen zu verwenden. Das ist wichtig, weil wir nicht nur die erste Ableitung (also die Geschwindigkeit), sondern auch die zweite Ableitung (die Beschleunigung) des Modell-Outputs nach der Zeit benötigen. Dabei werden mit tape.watch() alle Input-Zeiten (t_collocation, t_initial_pos) “überwacht”, damit wir deren Ableitungen berechnen können.
Und schließlich der Verlust durch physikalische Gesetze (ode_loss): Das Modell sagt die Position an den Kollokationspunkten (x_pred_collocation) voraus. Dann werden die erste Ableitung (dxdt_collocation, also die vom Modell vorhergesagte Geschwindigkeit) und die zweite Ableitung (d2xdt2_collocation, also die vom Modell vorhergesagte Beschleunigung) bezüglich der Zeit t_collocation berechnet. Diese Ableitungen werden dann in die physikalische Gleichung eingesetzt, in unserem Beispiel in die Gleichung für eine gedämpfte Schwingung: m⋅dt2d2x+c⋅dtdx+k⋅x=0. Der ode_loss misst dann, wie stark die linke Seite dieser Gleichung von Null abweicht. Wenn das Modell die Physik perfekt lernt, sollte dieser Verlust idealerweise Null sein.
Der Verlust durch Positionsdaten (loss_data_pos) funktioniert identisch zum DataOnlyModel. Hier findet ein direkter Vergleich der vom Modell vorhergesagten Position mit den echten Positionsdaten statt. Das Gleiche gilt für den Verlust durch Geschwindigkeitsdaten (loss_data_vel): Auch hier vergleichen wir die vom Modell abgeleitete Geschwindigkeit mit den echten Geschwindigkeitsdaten, wie im DataOnlyModel.
Der Gesamtverlust (total_loss) ist dann eine gewichtete Summe all dieser drei Verlustanteile. Die pinn_weights (w_p, w_d_pos, w_d_vel) bestimmen, wie stark das Modell auf die Erfüllung der Physik, die Übereinstimmung mit den Positionsdaten und die Übereinstimmung mit den Geschwindigkeitsdaten achten soll. Diese Gewichtungen sind wichtig für die Stabilität und Konvergenz von PINNs.
Einer der kritischen Aspekte bei PINNs ist die Balance zwischen verschiedenen Verlustkomponenten. In unserem Beispiel verwende ich folgende Gewichtungen:
Ich gewichte die Physik (w_p) mit 10.0 recht hoch, damit das Modell die physikalischen Gesetze strikt befolgt. Das Geschwindigkeits-Gewicht (w_d_vel) ist mit 5.0 stärker gewichtet als die Position, weil die Geschwindigkeitsinformation für die Dynamik wichtig ist. Für das Positions-Gewicht (w_d_pos) habe ich eine Basisgewichtung von 1.0 für die Startposition gewählt.
Eine falsche Gewichtung kann aber auch schnell mal zu Problemen führen: Zum Beispiel physikalisch inkonsistente Lösungen, wenn w_p zu niedrig ist, oder eine schlechte Anpassung an die Daten, wenn w_p zu hoch ist. Und im schlimmsten Fall kann es zu einem instabilen Training kommen, wenn die Verhältnisse unausgewogen sind.
Die optimale Gewichtung ist oft problemspezifisch und erfordert einiges an experimentellem Feintuning. Die obige Verteilung habe ich durch Ausprobieren definiert.
Abschließend werden wie gehabt die Gradienten des total_loss bezüglich der trainierbaren Parameter des Netzwerks berechnet und zur Aktualisierung der Gewichte des Modells verwendet.
Analytical Solution
Die Funktion analytical_solution dient dazu, die exakte Position eines gedämpften harmonischen Oszillators zu einem bestimmten Zeitpunkt t zu berechnen. Dabei berücksichtigt sie beliebige Anfangsbedingungen.
Schauen wir uns die Eingabeparameter mal genauer an:
t: Das ist der Zeitpunkt, für den wir die Position berechnen wollen.
system_params: Hierüber übergeben wir die Masse (m), Dämpfung (c) und Steifigkeit (k) des Systems.
x0: Die Anfangsposition des Oszillators zum Zeitpunkt t=0.
v0: Die Anfangsgeschwindigkeit des Oszillators zum Zeitpunkt t=0.
Im ersten Schritt berechnen wir die ungedämpfte Eigenfrequenz (omega_n=ωn) und den Dämpfungsgrad (zeta=ζ). Der Dämpfungsgrad ist wichtig, um festzustellen, welcher der drei Dämpfungsfälle vorliegt.
Die Kernlogik besteht aus einer Fallunterscheidung, je nachdem welcher Dämpfungsfall vorliegt. Wichtig ist, dass die Konstanten in den jeweiligen Lösungsformeln dynamisch aus den übergebenen x0 und v0 Werten berechnet werden.
Kritisch gedämpfter Fall (ζ ist nahe 1.0):
Die Konstanten C1 und C2 werden direkt aus x0 und v0 abgeleitet.
Die Position wird mit der Formel x(t)=(C1+C2t)e−ωnt berechnet.
Unterdämpfter Fall (ζ<1.0):
Die gedämpfte Eigenfrequenz ωd wird berechnet.
Die Konstanten C1 und C2 (die nun die Amplitude und Phase der Schwingung bestimmen) werden aus x0 und v0 abgeleitet.
Die Position wird mit der Formel x(t)=e−ζωnt(C1cos(ωdt)+C2sin(ωdt)) berechnet.
Überdämpfter Fall (ζ>1.0):
Die beiden charakteristischen Wurzeln α1 und α2 der Lösung werden berechnet.
Die Konstanten A1 und A2 werden durch das Lösen eines linearen Gleichungssystems, das durch x0 und v0 gegeben ist, bestimmt.
Die Position wird mit der Formel x(t)=A1eα1t+A2eα2t berechnet.
Die Funktion gibt dann die berechnete Position x des Oszillators zum Zeitpunkt tzuru¨ck,dienundiespezifischenAnfangsbedingungenx0undv0$ korrekt widerspiegelt.
Im Kontext von Machine Learning und Physik-informierten neuronalen Netzen dient diese erweiterte Funktion als “Ground Truth” oder Referenzlösung. Durch die größere Flexibilität können wir die Leistung der neuronalen Netze (insbesondere des PINN-Modells) unter einer breiteren Palette von Anfangsbedingungen evaluieren. Das ist wichtig, um die Robustheit und Generalisierungsfähigkeit des PINN zu gewährleisten.
CustomProgressLogger
Dieser Keras Callback dient dazu, den Fortschritt des Trainings zu protokollieren und auszugeben. Dabei kann ich mit dem log_interval festlegen, wie oft eine entsprechende Meldung ausgegeben werden soll.
class CustomProgressLogger(tf.keras.callbacks.Callback): def __init__(self, log_interval: int = 1000): super().__init__() self.log_interval = log_interval def on_epoch_end(self, epoch: int, logs: Dict[str, Any] = None): if logs is None: logs = {} if epoch % self.log_interval == 0 or epoch == self.params['epochs'] - 1: total_loss = logs.get('total_loss', 'N/A') physics_loss = logs.get('physics_loss', 'N/A') data_pos_loss = logs.get('data_pos_loss', 'N/A') data_vel_loss = logs.get('data_vel_loss', 'N/A') if 'physics_loss' in logs: print(f"Epoch {epoch:05d}: Total Loss: {total_loss:.4e}, " f"Physics Loss: {physics_loss:.4e}, " f"Pos Data Loss: {data_pos_loss:.4e}, " f"Vel Data Loss: {data_vel_loss:.4e}") else: print(f"Epoch {epoch:05d}: Total Loss: {total_loss:.4e}, " f"Pos Data Loss: {data_pos_loss:.4e}, " f"Vel Data Loss: {data_vel_loss:.4e}")
Die Ausgabe erfolgt immer am Ende einer Epoche, und zwar dann, wenn die Epochennummer ein Vielfaches des festgelegten log_interval ist oder wenn die letzte Epoche des Trainings erreicht wurde.
Was die Anzeige betrifft, so werden die verschiedenen Verlustwerte protokolliert: der Gesamtverlust, der Physikverlust sowie der Datenverlust für Position und Geschwindigkeit.
Die Ausgabe ist so formatiert, dass sie sich anpasst, je nachdem, ob es sich um ein PINN-Modell handelt, das ja einen Physikverlust hat, oder um ein rein datenbasiertes Modell.
Kurz gesagt: Es handelt sich um einen anpassbaren Fortschrittslogger, der mich während des Keras-Trainings gezielt über die wichtigsten Verlustwerte informiert.
prepare_data Funktion
Diese Funktion dient dazu, alle Zeitpunkte und Anfangswerte vorzubereiten, die wir für das Training unserer Modelle und das spätere Plotten der Ergebnisse benötigen.
Ich erstelle TensorFlow-Tensoren für die Anfangsposition x(0)=0 und die Anfangsgeschwindigkeit dtdx(0)=1. Zusätzlich generiere ich eine Reihe von gleichmäßig verteilten Zeitpunkten (t_collocation_pinn), die das PINN-Modell verwendet, um die physikalischen Gleichungen zu “überprüfen”.
Für die Visualisierung der Ergebnisse erstelle ich sowohl NumPy-Arrays als auch TensorFlow-Tensoren für die Zeitachse, die später verwendet werden, um die Vorhersagen zu generieren.
Die Funktion gibt dann ein Dictionary mit all diesen vorbereiteten Tensoren und NumPy-Arrays zurück. Sie sammelt und formatiert alle notwendigen Eingangsdaten (Anfangswerte, Zeitpunkte für Training und Plot) in einem zentralen Schritt.
train_model
Diese Funktion dient dazu, ein beliebiges Keras-Modell zu trainieren. Dabei kompiliere ich das übergebene model mit dem Adam-Optimierer und der angegebenen learning_rate.
def train_model( model: tf.keras.Model, dataset: tf.data.Dataset, epochs: int, learning_rate: float, early_stopping_config: Dict[str, Any], log_interval: int, model_name: str) -> tf.keras.callbacks.History: print(f"\n--- Training {model_name} Model ---") model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate)) callbacks = [] if model_name == "PINN" and early_stopping_config: early_stopping_callback = tf.keras.callbacks.EarlyStopping( monitor=early_stopping_config['monitor'], patience=early_stopping_config['patience'], min_delta=early_stopping_config['min_delta'], mode=early_stopping_config['mode'], verbose=early_stopping_config['verbose'], restore_best_weights=True ) callbacks.append(early_stopping_callback) progress_logger = CustomProgressLogger(log_interval=log_interval) progress_logger.params = {'epochs': epochs} callbacks.append(progress_logger) history = model.fit( dataset, steps_per_epoch=1, epochs=epochs, callbacks=callbacks, verbose=0 ) print(f"\n{model_name} Training finished after {len(history.history['total_loss'])} epochs.") return history
Zusätzlich füge ich noch ein paar Callbacks hinzu:
Einen EarlyStopping-Callback gibt es aber nur, wenn es sich um das “PINN”-Modell handelt und die Konfiguration dafür vorhanden ist. Dieser Callback sorgt dafür, dass das Training frühzeitig gestoppt wird, wenn sich der Verlust nicht mehr verbessert.
Den CustomProgressLogger füge ich immer hinzu. Er gibt den Trainingsfortschritt regelmäßig aus.
Anschließend rufe ich die fit-Methode des Modells auf, um das Training mit dem bereitgestellten dataset und den definierten callbacks zu starten. Die Standard-Keras-Ausgabe unterdrücke ich dabei (verbose=0), da der CustomProgressLogger die Ausgabe übernimmt.
Nach Abschluss des Trainings gibt es das history-Objekt zurück. In diesem Objekt sind Informationen über den Trainingsverlauf (z.B. Verlustwerte pro Epoche) enthalten.
Die Funktion kapselt den gesamten Trainingsprozess für ein Keras-Modell. Das beinhaltet die Kompilierung, das Anwenden von Callbacks und die eigentliche fit-Operation. Am Ende gibt sie den Trainingsverlauf zurück.
plot_results-Funktion
Die Funktion visualisiert die Ergebnisse, indem sie die Vorhersagen beider trainierter Modelle (PINN und datenbasiert) gegen die bekannte analytische Lösung und die ursprünglichen Trainingsdaten plotet.
Die plot_results-Funktion, erstellt einen Vergleichsplot, der alle wichtigen Elemente auf einen Blick vereint.
Der Hauptzweck ist ein visueller Vergleich aller drei Ansätze – analytisch, PINN und rein datenbasiert – in einem übersichtlichen Plot. So kann man direkt sehen, wie gut die Modelle im Vergleich zur exakten Lösung und zueinander abschneiden.
Die main-Funktion ist das Herzstück des Programms, sie steuert den gesamten Ablauf. Im Wesentlichen konfiguriert man hier alle wichtigen Parameter für das Training und die Visualisierung. Dazu gehören Dinge wie die Anzahl der Epochen, die Lernrate, verschiedene Gewichtungen und der Bereich, in dem die Ergebnisse geplott werden sollen.
Zuerst werden die physikalischen Parameter des Systems initialisiert, also Masse, Dämpfung und Steifigkeit. Danach rufe ich prepare_data auf. Diese Funktion erstellt alle TensorFlow-Tensoren, die später für das Training und das Plotten benötigt werden.
Anschließend kommt der spannende Teil: das Training der beiden Modelle.
PINN-Training: Zuerst initialisiere ich das PINNModel. Dann erzeuge ich das passende tf.data.Dataset und rufe train_model auf, um das PINN zu trainieren. Hier ist auch Early Stopping aktiviert, um ein Overfitting zu vermeiden.
Datenbasiertes NN-Training: Danach initialisiere ich das DataOnlyModel und erstelle das entsprechende tf.data.Dataset. Auch hier wird train_model aufgerufen, um das rein datenbasierte NN zu trainieren.
Nach dem Training generiere ich mit den trainierten Modellen Vorhersagen für den gesamten Plot-Zeitbereich. Zusätzlich berechne ich die analytische Lösung, um einen Vergleich zu haben.
Zum Schluss werden die Ergebnisse geplottet. Die Funktion plot_results stellt die Ergebnisse grafisch dar, sodass man PINN, datenbasiertes NN und die analytische Lösung direkt miteinander vergleichen kann.
Wenn alles durchgelaufen ist, gibt es noch eine Abschlussmeldung, die signalisiert, dass alle Schritte erfolgreich beendet wurden.
Training und Ergebnisse
Nun wird es aber Zeit die Modelle zu trainieren. Ich führe also das Skript aus und zunächst erhalte ich diese Ausgaben. Eine Interpretation erfolgt im nächsten Abschnitt.
Zunächst der Trainingsverlauf des PINNs.
--- Training PINN Model ---Epoch 00000: Total Loss: 1.1973e+02, Physics Loss: 1.1230e+01, Pos Data Loss: 0.0000e+00, Vel Data Loss: 1.4862e+00Epoch 01000: Total Loss: 2.6340e+00, Physics Loss: 1.0341e-01, Pos Data Loss: 9.6072e-03, Vel Data Loss: 3.1806e-01[...]Epoch 39000: Total Loss: 1.6668e-01, Physics Loss: 1.6599e-02, Pos Data Loss: 9.7122e-05, Vel Data Loss: 1.1815e-04Epoch 39791: early stoppingRestoring model weights from the end of the best epoch: 38791.PINN Training finished after 39791 epochs.
Und dann der Trainingsverlauf des datenbasierten NNs.
--- Training Data-Only NN Model ---Epoch 00000: Total Loss: 2.1020e+00, Pos Data Loss: 0.0000e+00, Vel Data Loss: 2.1020e+00Epoch 01000: Total Loss: 0.0000e+00, Pos Data Loss: 0.0000e+00, Vel Data Loss: 0.0000e+00Epoch 02000: Total Loss: 0.0000e+00, Pos Data Loss: 0.0000e+00, Vel Data Loss: 0.0000e+00Epoch 03000: Total Loss: 0.0000e+00, Pos Data Loss: 0.0000e+00, Vel Data Loss: 0.0000e+00Epoch 04000: Total Loss: 0.0000e+00, Pos Data Loss: 0.0000e+00, Vel Data Loss: 0.0000e+00Epoch 04999: Total Loss: 0.0000e+00, Pos Data Loss: 0.0000e+00, Vel Data Loss: 0.0000e+00Data-Only NN Training finished after 5000 epochs.
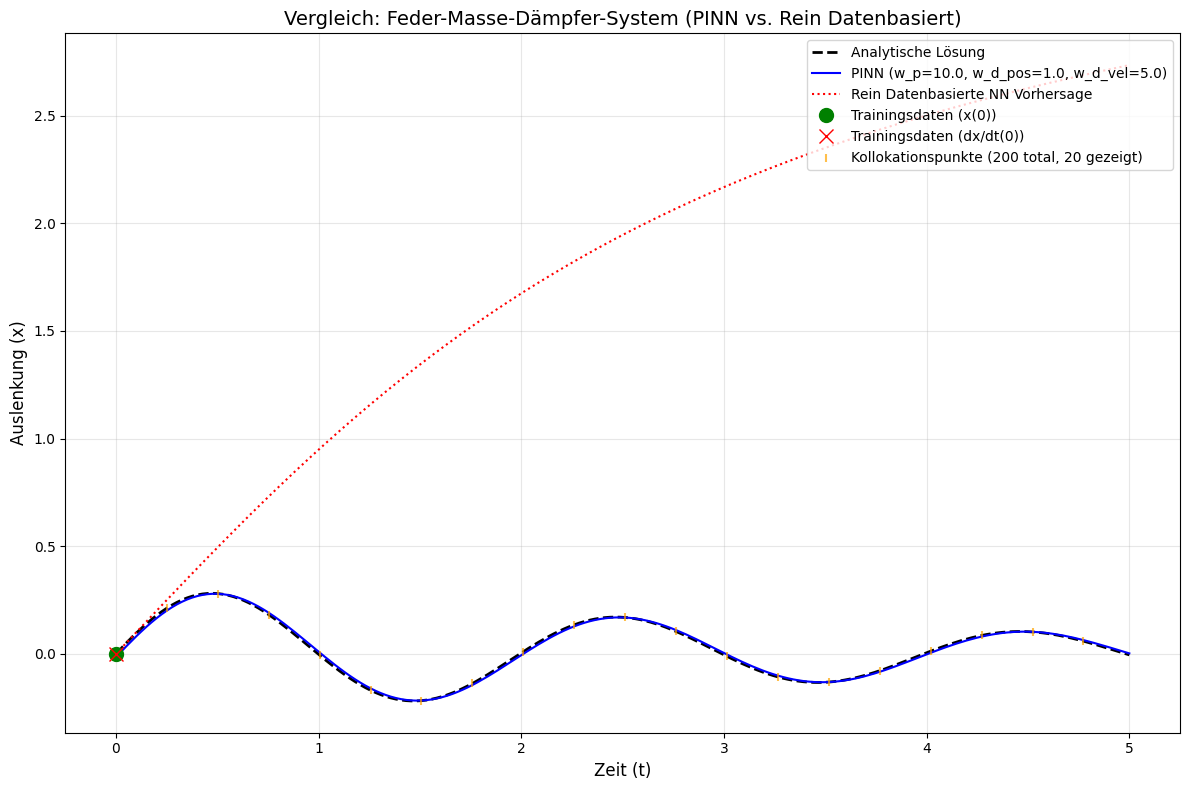
Und schließlich der durch die Funktion erzeugte Plot, der die Verläufe vergleicht.
Der direkte Vergleich
Im obigen Plot sind mehrere Kurven dargestellt, auf die ich im folgenden kurz eingehen möchte.
Analytische Lösung (schwarz gestrichelt): Die erwartete perfekt gedämpfte Sinusschwingung.
PINN (blau durchgezogen): Folgt der analytischen Lösung nahezu perfekt über den gesamten Zeitbereich, obwohl es dieselben spärlichen Anfangsdaten erhält. Die physikalische Verlustfunktion zwingt das Modell, eine Lösung zu finden, die die zugrunde liegende Dynamik des Feder-Masse-Dämpfer-Systems zu jedem Zeitpunkt erfüllt.
Ich habe ein paar Parameter gezielt so verändert, dass die Ergebnisse nicht mehr perfekt der analytischen Lösung entsprechen. So kann man aber alle Kurven besser sehen.
Datenbasiertes NN (rot gepunktet): Lernt nur aus den zwei extrem spärlichen Anfangsbedingungen. Ohne das Wissen um die physikalische Differentialgleichung kann es die komplexe Schwingungsbewegung nicht extrapolieren. Seine Vorhersage driftet nach den wenigen bekannten Punkten schnell in physikalisch unsinnige Bereiche ab.
Die “Null-Verluste” des datenbasierten Modells
Ein besonders aufschlussreicher Aspekt der Trainingsergebnisse ist, dass das datenbasierte Modell ab Epoche 1000 “Null-Verluste” liefert:
Epoch 01000: Total Loss: 0.0000e+00, Pos Data Loss: 0.0000e+00, Vel Data Loss: 0.0000e+00
Null-Verluste bedeuten nicht, dass das Modell perfekt ist, sondern dass es die wenigen Trainingsdaten (wir hatten ja nur zwei Anfangsbedingungen) auswendig gelernt hat. Das Modell ist stark überangepasst und kann nicht generalisieren.
Das passiert, weil wir zu wenige Datenpunkte im Verhältnis zur Modellkomplexität haben. Das Netz kann die spärlichen Daten einfach perfekt memorieren. Und ohne Regularisierung oder zusätzliche Constraints (wie die Physik im PINN) entstehen wild schwankende Vorhersagen zwischen den Datenpunkten.
Im Kontrast dazu das PINN: Es zeigt stabile, nicht-null Verluste, was ein gutes Zeichen ist. Der Physik-Verlust fungiert hier als natürliche Regularisierung und verhindert Overfitting durch kontinuierliche physikalische Constraints an den Kollokationspunkten.
Bei maschinellem Lernen mit spärlichen Daten sind Null-Verluste oft ein Zeichen für Probleme, nicht für Erfolg. PINNs lösen dieses Problem elegant, indem sie Domänenwissen integrieren.
Warum das PINN überlegen ist
Das PINN “kennt” die physikalische Gleichung des Systems. Selbst mit minimalen Daten wird es durch die physikalische Verlustfunktion gezwungen, eine Lösung zu finden, die den Gesetzen der Physik gehorcht. Das datenbasierte Modell hingegen “erfindet” eine Funktion, die die Startpunkte trifft, aber keine Ahnung von der zugrunde liegenden Dynamik hat.
Robustheit bei spärlichen Daten: Das PINN liefert physikalisch plausible Vorhersagen, auch wenn nur wenige Datenpunkte verfügbar sind.
Physikalische Konsistenz: Die Vorhersagen bleiben auch außerhalb der Trainingsdaten korrekt und vertrauenswürdig. Und genau das ist wichtig für reale Anwendungen, wo Daten oft unvollständig sind.
Der geringe, aber stabile Physik-Loss zeigt, dass das PINN die Physik “versteht”. Das macht es zu einem robusten und vertrauenswürdigen Werkzeug für wissenschaftliche und technische Anwendungen.
Grenzen und Herausforderungen von PINNs
Trotz ihrer beeindruckenden Fähigkeiten haben PINNs auch einige Limitationen, die man bei der praktischen Anwendung berücksichtigen sollte:
Rechenaufwand und Trainingszeit
PINNs sind deutlich langsamer zu trainieren als Standard-NNs. Das liegt an der komplexeren Verlustfunktion. Hier spielen mehrere Faktoren eine Rolle: Zum einen müssen Ableitungen zweiter Ordnung durch automatische Differenzierung berechnet werden. Zum anderen müssen die physikalischen Gleichungen an hunderten von Kollokationspunkten ausgewertet werden. Und schließlich braucht es mehrfache Rückwärtspropagation für verschiedene Verlustkomponenten.
In unserem Beispiel hat das PINN ungefähr 40.000 Epochen benötigt, während das datenbasierte NN bereits nach wenigen tausend Epochen “konvergierte” – auch wenn die Lösung, die es gefunden hat, falsch war.
Hyperparameter-Tuning:
Die Gewichtungsparameter erfordern oft viel Experimentieren. In unserem Fall:
Falsche Gewichtungen können zu verschiedenen Problemen führen: Sind die Gewichte für physikalische Randbedingungen zu niedrig angesetzt, erhält man physikalisch inkonsistente Lösungen. Sind sie hingegen zu hoch, werden die Trainingsdaten ignoriert. Und unausgewogene Verhältnisse führen schnell zu einem instabilen Training.
Das optimale Verhältnis ist stark problemspezifisch und erfordert systematisches Experimentieren.
Komplexe Partielle Differentialgleichungen (PDE): Grenzen der Skalierbarkeit
Bei sehr komplexen physikalischen Systemen können PINNs an ihre Grenzen stoßen. Schauen wir uns konkrete Beispiele an:
Navier-Stokes-Gleichungen für dreidimensionale Strömungen mit Turbulenzen:∂t∂u+(u⋅∇)u=−ρ1∇p+ν∇2u∇⋅u=0
Hier hat man vier gekoppelte Variablenu(x,y,z,t), v(x,y,z,t), w(x,y,z,t), p(x,y,z,t) mit nichtlinearen Termen wie (u⋅∇)u. Bei Turbulenz entstehen chaotische, multiskalige Strukturen, die extrem schwer zu lernen sind.
Das PINN müsste zwei verschiedene physikalische Domänen gleichzeitig lernen und deren Wechselwirkung an der GrenzflächeΓ korrekt modellieren.
Systeme mit scharfen Gradienten (Schockwellen):∂t∂u+∂x∂f(u)=0
Bei Schockwellen entstehen Diskontinuitäten, die Lösung “springt” abrupt. Standard-NNs und damit auch PINNs haben Schwierigkeiten mit solchen nicht-glatten Lösungen.
In solchen Fällen können traditionelle numerische Methoden mit spezialisierter Diskretisierung (finite Volumen für Schocks, adaptive Gitter für Multiskalen-Probleme) durchaus überlegen sein.
Doch PINNs müssen nicht bei einfachen Beispielen wie unserem Feder-Masse-Dämpfer-System stehenbleiben. Die grundlegenden Konzepte, die wir kennengelernt haben - die physikalische Verlustfunktion, Kollokationspunkte und automatische Differenzierung - lassen sich auf deutlich komplexere und mächtigere Anwendungen erweitern.
Erweiterte PINN-Konzepte
Multi-Output PINNs: Gekoppelte Systeme
Unser Feder-Masse-Dämpfer-Beispiel modellierte nur eine Variable (Position x). Reale physikalische Systeme haben aber oft mehrere gekoppelte abhängige Variablen, die gleichzeitig gelöst werden müssen.
Nehmen wir mal die 2D-Wärmeleitung mit gekoppeltem Wärmefluss als Beispiel:
Das Problem dabei: Das PINN muss gleichzeitig die TemperaturverteilungT(x,y,t) und den Wärmeflussq(x,y,t) lernen. Und das Schwierige ist, dass beide Größen durch das Fourier’sche Gesetz gekoppelt sind – der Wärmefluss hängt direkt vom Temperaturgradienten ab.
Die PINN-Lösung sieht dann so aus: Das Netzwerk hat multiple Ausgänge und lernt alle Variablen simultan. Die Physics-Loss-Funktion enthält beide physikalischen Gleichungen als Constraints. Dadurch stellen wir sicher, dass:
Die Temperatur der Wärmeleitungsgleichung folgt.
Der Wärmefluss korrekt aus dem Temperaturgradienten berechnet wird.
Beide Größen physikalisch konsistent bleiben.
Das Ganze ist so komplex, weil wir drei gekoppelte PDEs haben, die gleichzeitig erfüllt werden müssen. Außerdem brauchen wir partielle Ableitungen in alle Raumrichtungen (∂x∂, ∂y∂, ∂t∂). Und natürlich muss die Konsistenz zwischen den Variablen gewährleistet sein.
Die Vorteile liegen aber auf der Hand: Physikalische Kopplungen werden automatisch berücksichtigt und wir bekommen eine konsistente Lösung aller Variablen gleichzeitig. Das ist natürlich effizienter, als separate Modelle für jede Variable zu erstellen.
Doch selbst bei Multi-Output PINNs bleibt eine wichtige Frage: Wo genau sollen die Kollokationspunkte platziert werden? In unserem Feder-Masse-Dämpfer-Beispiel haben wir 200 gleichmäßig verteilte Punkte verwendet. Das war zwar einfach, aber nicht unbedingt die beste Strategie.
Eine Möglichkeit, die Performance von PINNs weiter zu verbessern, ist die adaptive Punktverteilung. Hier gibt es verschiedene Strategien:
Fehler-basiert: Mehr Punkte dort, wo der Physics-Loss besonders hoch ist. Das erscheint erstmal logisch.
Gradienten-basiert: Eine dichtere Punktverteilung in Bereichen mit steilen Gradienten.
Residual-basiert: Der Fokus liegt auf Bereichen, in denen die zugrundeliegende physikalische Gleichung schlecht erfüllt wird.
Multi-fidelity: Eine Kombination aus groben und feinen Auflösungen. Man könnte also erst eine grobe Lösung berechnen und dann in bestimmten Bereichen die Auflösung erhöhen.
Die Vorteile einer solchen adaptiven Kollokation liegen auf der Hand: Eine bessere Konvergenz mit weniger Gesamtpunkten, eine automatische Fokussierung auf “schwierige” Bereiche und letztendlich eine reduzierte Rechenzeit bei verbesserter Genauigkeit.
Diese fortgeschrittenen Konzepte zeigen das Potenzial von PINNs für komplexe, reale Anwendungen. Sie demonstrieren, wie PINNs über einfache Einzelvariablen-Probleme hinausgehen und zu einem mächtigen Werkzeug für die moderne wissenschaftliche Modellierung werden können.
Zusammenfassung
In diesem Artikel haben wir uns ausführlich mit Physik-Informierten Neuronalen Netzen (PINNs) beschäftigt, und zwar von den theoretischen Grundlagen bis hin zur praktischen Umsetzung.
Wir haben die Kernkonzepte erarbeitet und wir haben verstanden, wie PINNs die Flexibilität von Neuronalen Netzen mit physikalischen Gesetzen kombinieren. Dabei haben wir gesehen, dass die automatische Differenzierung komplexe Ableitungsberechnungen erst praktikabel macht. Außerdem haben wir uns angeschaut, wie Kollokationspunkte die physikalische Konsistenz über den gesamten Definitionsbereich erzwingen und wie eine Multi-Komponenten-Verlustfunktion das Daten-Fitting und die physikalischen Constraints ausbalanciert.
Im Anschluss habe ich eine vollständige TensorFlow-Implementierung für ein Feder-Masse-Dämpfer-System gezeigt und einen direkten Vergleich zwischen einem PINN und einem rein datenbasierten NN mit identischen, spärlichen Daten durchgeführt. Dabei hat sich herausgestellt, dass das Tuning der Gewichtungsparameter ein kritischer Erfolgsfaktor ist und dass Performance-Optimierungen durch @tf.function und tf.GradientTape möglich sind.
Aus den Experimenten konnten wir einige wichtige Erkenntnisse gewinnen: “Null-Verluste” sind bei spärlichen Daten ein Warnsignal, nicht etwa ein Erfolg. PINNs generalisieren robust, auch außerhalb der Trainingsdaten, und physikalische Constraints wirken als natürliche Regularisierung. Allerdings ist der erhöhte Rechenaufwand der Preis, den man für die physikalische Konsistenz zahlen muss.
Natürlich gibt es auch Grenzen und weiteres Potenzial. So gibt es Skalierungsgrenzen bei komplexen PDEs (z.B. Navier-Stokes), und die Hyperparameter-Sensitivität erfordert systematisches Experimentieren. Erweiterte Konzepte wie Multi-Output PINNs und adaptive Kollokationspunkte sind ebenfalls vielversprechend.
Zusammenfassend lässt sich sagen, dass PINNs ein mächtiges Werkzeug für wissenschaftliche ML-Anwendungen sind, besonders wertvoll bei spärlichen Daten und physikalischen Constraints. Sie überbrücken erfolgreich die Lücke zwischen datengetriebenem ML und physikalischem Verständnis – ein wichtiger Schritt hin zu einer vertrauenswürdigen KI in kritischen Anwendungen.
Dieser Artikel liefert sowohl das theoretische Verständnis als auch die praktischen Implementierungsfähigkeiten, die man für den Einstieg in PINNs benötigt.