All documents for this post can be found in my repository.
Day 22 makes the system “intelligent”. Day 20 brought the interactive dashboard and the mole game. The mole is randomly selected and receives secret sabotage instructions. The user then has to manually guess who the mole is. The problem is obvious. With four agents, the success rate of pure guessing is 25 percent. Day 22 solves this “problem” with automatic detection. The system analyzes agent behavior and looks for suspicious patterns. Of course, we could do this manually, but then we wouldn’t have much left to do. The programmatic solution combines rule-based analysis with an LLM. Better than chance and smarter than pure rules. At least I hope so 😅
Mole Game Mechanics
Day 20 introduced the basic mechanics for the mole game.
At session start, a random agent is selected as the mole. This agent is assigned a sabotage pattern. There are five different strategies. The other agents naturally don’t know who the mole is.
The mole receives their secret instructions via system prompt. These instructions are automatically injected into the context on first response.
The five sabotage strategies work differently. With TIMING_ERRORS, the mole deliberately gives wrong time estimates and contradicts themselves later. With FALSE_INFO, they spread subtle misinformation about guard patterns and security systems. With COORDINATION_CHAOS, they give confusing and contradictory coordination instructions. With SUBTLE_DELAYS, they deliberately hesitate, ask unnecessarily many questions, and thereby slow down planning. With WRONG_TOOLS, they suggest tools that simply don’t fit the job.
After the heist ends, the user can indicate their suspicion. The HeistController then evaluates the result. SUCCESS means, surprisingly, the user guessed correctly. FAILURE means they were wrong. BUSTED means the user didn’t express any suspicion at all.
Tool Execution
Day 22 also reactivates tool execution, which has been inactive since Day 16. Day 13 already had complete tool-calling functionality with the [OAUTH_TOOL:name:param] pattern. Day 16 then integrated the system, but tools were only mentioned in the system prompt and never actually executed.
Now agents can call tools with the [TOOL:name:param] pattern. The safecracker can use [TOOL:calculator:50*2]. The hacker can use [TOOL:file_reader:vault_specs.txt]. The intel can use [TOOL:database_query:SELECT * FROM guards WHERE shift='night'].
Tool calls are automatically detected, executed with OAuth, and results are logged in the tool_usage table. The dashboard now shows tool statistics. This data flows into AI detection, as unusual tool usage is an important indicator of sabotage.
AI Detection System
Today we’re adding automatic mole detection. The system analyzes agent behavior during the heist and calculates suspicion scores. A RAG approach is used that combines rule-based pattern detection with LLM reasoning.
The process has three steps. First, retrieval, where rule-based analyses find suspicious patterns in messages and tool usage. Then augmentation, where these patterns are prepared as structured context. Finally, generation, where an LLM analyzes the conversation with this context and generates informed scores.
Pure rules would be too rigid and would miss subtle sabotage. Pure LLMs hallucinate and invent suspicions that don’t exist. The combination of both uses the strengths of both approaches. Rules find measurable anomalies, the LLM understands context and nuances.
The final combination uses 60 percent rule-based scores and 40 percent LLM scores. This weighting hopefully results in robust detection that works better than either approach alone. We’ll see 🤷♂️
Detection Signals
There are four main categories for rule-based pattern detection.
- Tool Usage Anomalies have a weight of 25 percent. This analyzes whether an agent has a lower success rate than average. Whether they suggest wrong tools or whether their tool patterns are unusual.
- Timing Inconsistencies have a weight of 30 percent. Here timing keywords in messages are counted. Contradictions and corrections are detected. Patterns like wait actually or nevermind are suspicious.
- Message Anomalies have a weight of 20 percent. Message length is analyzed. Signs of hesitation like hmm, uh, or let me think are counted. Deviating language patterns stand out.
- Information Quality also has a weight of 25 percent. The system distinguishes between vague and concrete information. Keywords like maybe, probably, or not sure are warning signals. Few specific details are suspicious.
These signals form the Retrieved Context (the R in RAG), which is then made available to the LLM. The weights were arbitrarily chosen by me. Why? Just because. We’ll see if it works.
RAG-based Sabotage Detector
The SabotageDetector class combines rule-based analyses with an LLM. I haven’t mentioned it in a while, but the local LLM is also being used here again 😉
class SabotageDetector:
def __init__(self, use_llm: bool = True):
# Weights for rule-based scoring
self.weights = {
"tool_usage_anomaly": 0.25,
"timing_inconsistency": 0.30,
"message_anomaly": 0.20,
"information_quality": 0.25
}
# RAG settings
self.use_llm = use_llm
self.llm_weight = 0.4 # 40% LLM
self.rule_weight = 0.6 # 60% Rules
# LLM client (LM Studio)
self.llm_client = OpenAI(
base_url="http://localhost:1234/v1",
api_key="not-needed"
)
def analyze_session(
self,
session_id: str,
messages: List[Dict],
tool_usage: List[Dict],
agents: List[str]
) -> Dict[str, float]:
# STEP 1: RETRIEVAL
rule_scores = self._get_rule_based_scores(
messages, tool_usage, agents
)
# STEP 2 & 3: AUGMENTATION + GENERATION
if self.use_llm:
llm_scores = self._get_llm_scores(
messages, tool_usage, agents, rule_scores
)
# Combine scores
combined_scores = {}
for agent in agents:
combined_scores[agent] = (
rule_scores[agent] * self.rule_weight +
llm_scores[agent] * self.llm_weight
)
return combined_scores
else:
return rule_scoresThe weights for rule-based scoring are defined in a dictionary. The RAG settings are configured. The LLM weight is set to 40 percent and the rule weight to 60 percent. The LLM client connects to an LM Studio instance on localhost port 1234.
The analyze_session method executes the complete process. Step 1 is retrieval, where rule-based pattern detection provides the rule_scores. Steps 2 and 3 are augmentation and generation. If the LLM is activated, additional LLM scores are calculated. The final scores are then combined from 60 percent rules and 40 percent LLM, resulting in the combined_scores.
I’m curious how, or rather if, this will work out. Let’s move on to the further implementation.
Step 1: Retrieval
In the first step, rule-based analyses are performed to identify suspicious patterns. These form the basis for the later LLM analysis.
Rule-based Score Calculation
This method calculates individual scores for each agent. Tool usage is analyzed, timing patterns are examined, message anomalies are detected, and information quality is evaluated.
def _get_rule_based_scores(self, messages, tool_usage, agents):
# Calculate individual scores
tool_scores = self._analyze_tool_usage(tool_usage, agents)
timing_scores = self._analyze_timing_patterns(messages, agents)
message_scores = self._analyze_message_anomalies(messages, agents)
info_scores = self._analyze_information_quality(messages, agents)
# Combine with weights
suspicion_scores = {}
for agent in agents:
suspicion_scores[agent] = (
tool_scores[agent] * self.weights["tool_usage_anomaly"] +
timing_scores[agent] * self.weights["timing_inconsistency"] +
message_scores[agent] * self.weights["message_anomaly"] +
info_scores[agent] * self.weights["information_quality"]
)
return suspicion_scoresThese scores form the Retrieved Context. They are measurable suspicions that will later help the LLM judge better.
The individual scores are then combined with the defined weights. Each agent receives a suspicion score between 0.0 and 1.0.
Tool Usage Analysis
Tool usage is counted for each agent. Both success and failure events are tracked.
def _analyze_tool_usage(self, tool_usage, agents):
# Count tool usage per agent
agent_tools = defaultdict(list)
for usage in tool_usage:
agent_tools[usage["agent"]].append({
"tool": usage["tool_name"],
"success": usage["success"]
})
# Calculate average success rate
total_tools = sum(len(tools) for tools in agent_tools.values())
total_success = sum(
sum(1 for t in tools if t["success"])
for tools in agent_tools.values()
)
avg_success_rate = total_success / total_tools if total_tools > 0 else 0
# Score agents below average
scores = {agent: 0.0 for agent in agents}
for agent, tools in agent_tools.items():
if len(tools) == 0:
continue
successes = sum(1 for t in tools if t["success"])
agent_success_rate = successes / len(tools)
if agent_success_rate < avg_success_rate:
deviation = (avg_success_rate - agent_success_rate) / avg_success_rate
scores[agent] = min(deviation * 1.5, 1.0)
return scoresThe average success rate is calculated across all agents. This gives us a baseline value.
Agents with a below-average tool success rate are suspicious. The reason is that the mole probably deliberately suggests wrong tools or uses the right tools incorrectly to sabotage the mission.
The deviation from average is calculated and multiplied by factor 1.5. This amplification factor was arbitrarily chosen and makes detection more sensitive. A deviation of 20 percent thus becomes a score of 0.3 instead of 0.2. The maximum is capped at 1.0. We may find that we need to correct the factor back to 1.0.
Timing Analysis
Timing keywords are defined as a list. Words like minute, hour, time, rush, wait, and delay. This list is simple and could be extended with NLP libraries like spaCy or sentence-transformers. This would also automatically capture synonyms and related terms. For this prototype, however, the simple keyword list is sufficient.
def _analyze_timing_patterns(self, messages, agents):
timing_keywords = ["minute", "hour", "time", "rush", "wait", "delay"]
contradiction_keywords = ["actually", "wait", "wrong", "change", "nevermind"]
agent_timing_mentions = defaultdict(int)
agent_contradictions = defaultdict(int)
for msg in messages:
text = msg["message"].lower()
agent = msg["agent_name"]
timing_count = sum(1 for kw in timing_keywords if kw in text)
contradiction_count = sum(1 for kw in contradiction_keywords if kw in text)
agent_timing_mentions[agent] += timing_count
agent_contradictions[agent] += contradiction_count
# Normalize
max_timing = max(agent_timing_mentions.values()) if agent_timing_mentions else 1
max_contradictions = max(agent_contradictions.values()) if agent_contradictions else 1
scores = {}
for agent in agents:
timing_ratio = agent_timing_mentions[agent] / max_timing
contradiction_ratio = agent_contradictions[agent] / max_contradictions
scores[agent] = (timing_ratio * 0.5 + contradiction_ratio * 0.5)
return scoresContradictions are also defined. Words like actually, wait, wrong, change, and nevermind.
For each message, it’s then counted how often these keywords occur. The number of timing mentions and contradictions is totaled for each agent.
Agents who frequently talk about timing and often contradict themselves are particularly suspicious. This is a typical pattern of the timing error sabotage strategy.
The values are normalized at the end and brought to a range of 0.0 to 1.0. The final score is composed 50 percent each of the timing ratio and the contradiction ratio.
Message Anomaly Analysis
For each agent, the average message length is calculated and compared to the overall average.
def _analyze_message_anomalies(self, messages, agents):
agent_messages = defaultdict(list)
for msg in messages:
agent_messages[msg["agent_name"]].append(msg["message"])
# Calculate average message length
all_lengths = [len(msg["message"]) for msg in messages]
avg_length = sum(all_lengths) / len(all_lengths) if all_lengths else 0
std_dev = (sum((l - avg_length) ** 2 for l in all_lengths) / len(all_lengths)) ** 0.5
scores = {agent: 0.0 for agent in agents}
for agent, msgs in agent_messages.items():
agent_avg_length = sum(len(msg) for msg in msgs) / len(msgs)
# Deviation from average
if std_dev > 0:
deviation = abs(agent_avg_length - avg_length) / std_dev
scores[agent] = min(deviation / 2.0, 1.0)
# Hesitation markers
hesitation_markers = ["hmm", "uh", "um", "wait", "let me think"]
hesitation_count = sum(
msg.lower().count(marker)
for msg in msgs
for marker in hesitation_markers
)
hesitation_ratio = hesitation_count / len(msgs)
scores[agent] = max(scores[agent], hesitation_ratio)
return scoresThe deviation from the overall average is then determined. Very long messages can be suspicious because the mole explains too much. Very short messages can be suspicious because they deliberately say little.
Additionally, hesitations are counted. Keywords like hmm, uh, um, wait, and let me think.
The mole often thinks longer because they have to plan their sabotage. Or they deliberately hesitate to waste time. These hesitations are therefore an important signal. At least in my understanding.
The final score for each agent is the higher value of deviation score and hesitation ratio.
Information Quality Analysis
The quality of information an agent provides can be an important indication of sabotage. Vague statements often indicate deliberate obfuscation.
def _analyze_information_quality(self, messages, agents):
concrete_keywords = ["camera", "guard", "vault", "door", "code", "key"]
vague_keywords = ["maybe", "probably", "might", "not sure", "i think"]
agent_concrete = defaultdict(int)
agent_vague = defaultdict(int)
for msg in messages:
text = msg["message"].lower()
agent = msg["agent_name"]
concrete_count = sum(1 for kw in concrete_keywords if kw in text)
vague_count = sum(1 for kw in vague_keywords if kw in text)
agent_concrete[agent] += concrete_count
agent_vague[agent] += vague_count
scores = {agent: 0.0 for agent in agents}
for agent in agents:
total = agent_concrete[agent] + agent_vague[agent]
if total > 0:
vagueness_ratio = agent_vague[agent] / total
scores[agent] = vagueness_ratio
return scoresConcrete keywords are defined as a list. Terms like camera, guard, vault, door, code, and key, which are very specific.
Vague keywords are also defined. Terms like maybe, probably, might, not sure, and i think, which are indefinite.
For each agent, it’s then counted how often they use concrete versus vague keywords. This provides insight into the quality of their information. Or their abilities 😅
The mole often deliberately gives vague information instead of concrete details. A sentence like maybe the guards are in the break room is much more indefinite than Guards are at position X in sector 3.
The score for each agent is the ratio of vague terms. That is, vague keywords divided by the total number of keywords.
Step 2: Augmentation
In the second step, the found patterns are prepared as structured context. This gives the LLM concrete starting points instead of just raw data.
Context Builder
This method structures the findings from step 1 into a clear format that the LLM can use for its analysis.
def _build_rag_context(self, messages, tool_usage, agents, rule_scores):
"""Build structured context from retrieved patterns."""
context_parts = []
# Top suspects from rule-based analysis
sorted_suspects = sorted(
rule_scores.items(),
key=lambda x: x[1],
reverse=True
)[:3]
context_parts.append("TOP SUSPECTS (Rule-based):")
for agent, score in sorted_suspects:
context_parts.append(f" - {agent}: {score:.2%} suspicion")
# Tool failures per agent
tool_failures = defaultdict(int)
for usage in tool_usage:
agent = usage.get("agent")
if not usage.get("success", True):
tool_failures[agent] += 1
if tool_failures:
context_parts.append("\nTOOL FAILURES:")
for agent, failures in tool_failures.items():
context_parts.append(f" - {agent}: {failures} tools failed")
# Timing keywords per agent
timing_mentions = defaultdict(int)
timing_keywords = ["minute", "hour", "time", "wait", "delay"]
for msg in messages:
agent = msg.get("agent_name")
text = msg.get("message", "").lower()
if any(kw in text for kw in timing_keywords):
timing_mentions[agent] += 1
if timing_mentions:
context_parts.append("\nTIMING-RELATED MENTIONS:")
top_timing = sorted(
timing_mentions.items(),
key=lambda x: x[1],
reverse=True
)[:3]
for agent, count in top_timing:
context_parts.append(f" - {agent}: {count} timing mentions")
return "\n".join(context_parts)This method creates structured context from the previously determined patterns.
The main suspects from rule-based analysis are extracted. These are the three agents with the highest suspicion score.
Failed tool calls are counted per agent. Only tools that actually failed are considered.
Mentions of timing are also counted. Agents who talk about timing particularly often thus stand out.
The resulting context gives the LLM concrete facts for analysis. Instead of just getting the raw conversation, it receives structured hints about suspicious behavior.
Step 3: Generation
In the third step, the LLM takes over the final analysis. It evaluates the conversation taking into account the structured context from steps one and two.
LLM-based Score Calculation
This method uses the LLM to analyze the agent conversation in the context of rule-based findings.
def _get_llm_scores(self, messages, tool_usage, agents, rule_scores):
"""LLM based analysis with Retrieved Context."""
# Build augmented context
context = self._build_rag_context(
messages, tool_usage, agents, rule_scores
)
# Build conversation
conversation_text = "\n".join([
f"{msg['agent_name']}: {msg['message']}"
for msg in messages[:50]
])
# RAG Prompt
prompt = f"""You are an expert detective analyzing a heist mission.
RETRIEVED SUSPICIOUS PATTERNS:
{context}
AGENT CONVERSATION:
{conversation_text}
TASK:
Analyze the conversation using the suspicious patterns above.
For each agent, estimate sabotage probability (0.0-1.0).
Consider:
- Vague or conflicting information
- Delays or confusion
- Suspicious tool failures
- Contradictions
Respond ONLY with JSON: {{"agent": score, ...}}
"""
response = self.llm_client.chat.completions.create(
model="local-model",
messages=[
{"role": "system", "content": "You are a detective. Respond only with valid JSON."},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=500
)
# Parse and normalize LLM scores
llm_output = response.choices[0].message.content.strip()
llm_scores = json.loads(llm_output)
return {
agent: max(0.0, min(1.0, float(llm_scores.get(agent, 0.0))))
for agent in agents
}The enriched context is created using the previously described method and contains all structured patterns.
The conversation is formatted. Only the first 50 messages are used to avoid overloading the context.
The prompt is constructed and is crucial for the quality of LLM analysis. The LLM doesn’t just get the raw conversation. It additionally receives the structured suspicions from rule-based analysis. This enrichment prevents the LLM from hallucinating and makes the analysis significantly more founded.
The LLM is asked to act as an expert detective and analyze the conversation. It should use the suspicious patterns as a basis.
The response is expected in JSON format. This allows easy parsing of results. The format is a dictionary with agent names as keys and scores as values between 0.0 and 1.0.
The temperature is set to 0.3. This makes responses more deterministic and reproducible.
The LLM scores are parsed and normalized to the valid range of 0.0 to 1.0.
Hybrid Approach: Rules and LLM
A purely rule-based approach is not flexible enough and too rigid. While it can help in many other cases, subtle sabotage, for example, wouldn’t be detected because the context isn’t recognized. Fixed thresholds don’t work for all situations.
On the other hand, an approach based purely on LLMs is also unsuitable because LLMs are known to hallucinate.
The combination of both makes the difference. Rules find measurable anomalies. The LLM understands context and nuances. Together, the scores are more robust and you still have full transparency.
The weighting is 60 percent rules and 40 percent LLM. Stable meets intelligent. Measurable meets context-aware. Hopefully this results in the best accuracy in detection.
Detection API
The detection API brings AI analysis directly into the frontend. We’re also building on code from previous days here.
from day_22.sabotage_detector import SabotageDetector
from day_20.session_analytics import SessionAnalytics
app = FastAPI(title="Sabotage Detection API")
analytics = SessionAnalytics()
detector = SabotageDetector()
@app.post("/api/ai-detect/analyze")
async def analyze_session(request: DetectionRequest):
# Get session data
details = analytics.get_session_details(request.session_id)
messages = details["messages"]
tool_usage = details["tool_usage"]
# Extract agents
agents = list(set(
msg["agent_name"]
for msg in messages
if msg.get("agent_name")
))
# Run detection
analysis = detector.get_detailed_analysis(
session_id=request.session_id,
messages=messages,
tool_usage=tool_usage,
agents=agents
)
return analysisThe endpoint first fetches data from the analytics database. These are the messages and tool usage events.
The agent list is extracted from the messages. Only unique agent names are used.
The detector is then called and analyzes the complete session. It executes the entire process, from retrieval through augmentation to generation.
The resulting analysis is returned as JSON.
Response Format
The API delivers a detailed analysis with scores and breakdown for each agent.
{
"session_id": "game_001",
"suggested_mole": "hacker",
"confidence": 0.647,
"suspicion_scores": {
"planner": 0.231,
"hacker": 0.647,
"safecracker": 0.189,
"getaway_driver": 0.274
},
"score_breakdown": {
"hacker": {
"tool_usage": 0.450,
"timing": 0.850,
"message_anomaly": 0.620,
"information_quality": 0.670,
"combined": 0.647
}
},
"analysis_weights": {
"tool_usage_anomaly": 0.25,
"timing_inconsistency": 0.30,
"message_anomaly": 0.20,
"information_quality": 0.25
}
}The numbers in this example are of course just for illustration. In this example, the hacker has the highest suspicion value at 0.647 and is therefore suggested as the mole.
The breakdown shows that timing analysis with 0.850 was the strongest signal. The hacker talked a lot about timing and often contradicted themselves.
The other categories also show suspicious values. Tool usage is at 0.450, message anomalies at 0.620, and information quality at 0.670.
The combined value of 0.647 is the weighted combination of all these signals according to the defined weights.
Integration into Mole Game
The detection system can be directly integrated into the mole game. The JavaScript part is again 100% vibecoded.
// After heist ends
const detection_result = await fetch('/api/ai-detect/suggest', {
method: 'POST',
body: JSON.stringify({ session_id: currentSession })
})
const data = await detection_result.json()
console.log(`AI suggests: ${data.suggested_mole}`)
console.log(`Confidence: ${data.confidence * 100}%`)
// Show to user as hint
if (data.confidence > 0.6) {
showHint(
`The AI is ${Math.round(data.confidence*100)}% confident ` +
`that ${data.suggested_mole} is the mole`
)
}After the heist ends, the detection API is called and delivers a suggestion.
The AI suggestion is shown to the user as a hint. However, only if the confidence is above 60 percent.
The user can then use this AI suggestion or ignore it and still guess themselves.
Measuring Accuracy
To measure whether the system is actually better than chance, there’s a simple test.
correct_detections = 0
total_games = 0
for game in completed_games:
detection = detector.suggest_mole(game.suspicion_scores)
if detection[0] == game.actual_mole:
correct_detections += 1
total_games += 1
accuracy = correct_detections / total_games
random_baseline = 1 / len(agents) # 0.25 with 4 agents
print(f"Detection Accuracy: {accuracy*100:.1f}%")
print(f"Random Baseline: {random_baseline*100:.1f}%")
print(f"Better than random: {accuracy > random_baseline}")For each completed game, the AI suggestion is compared with the actual mole. The number of correct detections is counted and divided by the total. The random baseline is 1 divided by the number of agents, or in other words the probability of being right when guessing. With four agents, that’s 25 percent.
The goal is to achieve an accuracy of at least 35 to 40 percent with 4 agents with our automated detection. This would make the system better than random guessing.
Let’s now talk about how to use all this.
Usage
The detection server is started with a simple command.
./day_22/start_detection_dashboard.shThe server then runs on port 8008 and replaces the old Day 20 dashboard.
The dashboard can be opened in the browser.
http://localhost:8008
The dashboard has a “Quick Start Heist” button. Clicking it automatically loads all available agents from the config and starts a new session. One of the agents is randomly made the mole. The agents then run in the background and their messages are streamed live to the dashboard.
The default config contains 6 agents: planner, hacker, safecracker, intel, driver, and lookout. New agents can simply be added to day_20/agents_config.yaml. The quick-start button will then recognize them automatically.
The dashboard offers some control over the running game. With Pause, the game can be paused. Resume continues it. Stop ends the game completely. The agents react immediately to these commands. Well, almost immediately. The current LLM call must be executed first.
The dashboard shows agent activity and tool usage in real-time. After a few turns, AI analysis can be started.
In addition to AI analysis, there’s also manual detection. All 6 agents are displayed as clickable badges. A click marks the agent as suspect. The reveal button then shows the actual mole including their sabotage strategy.
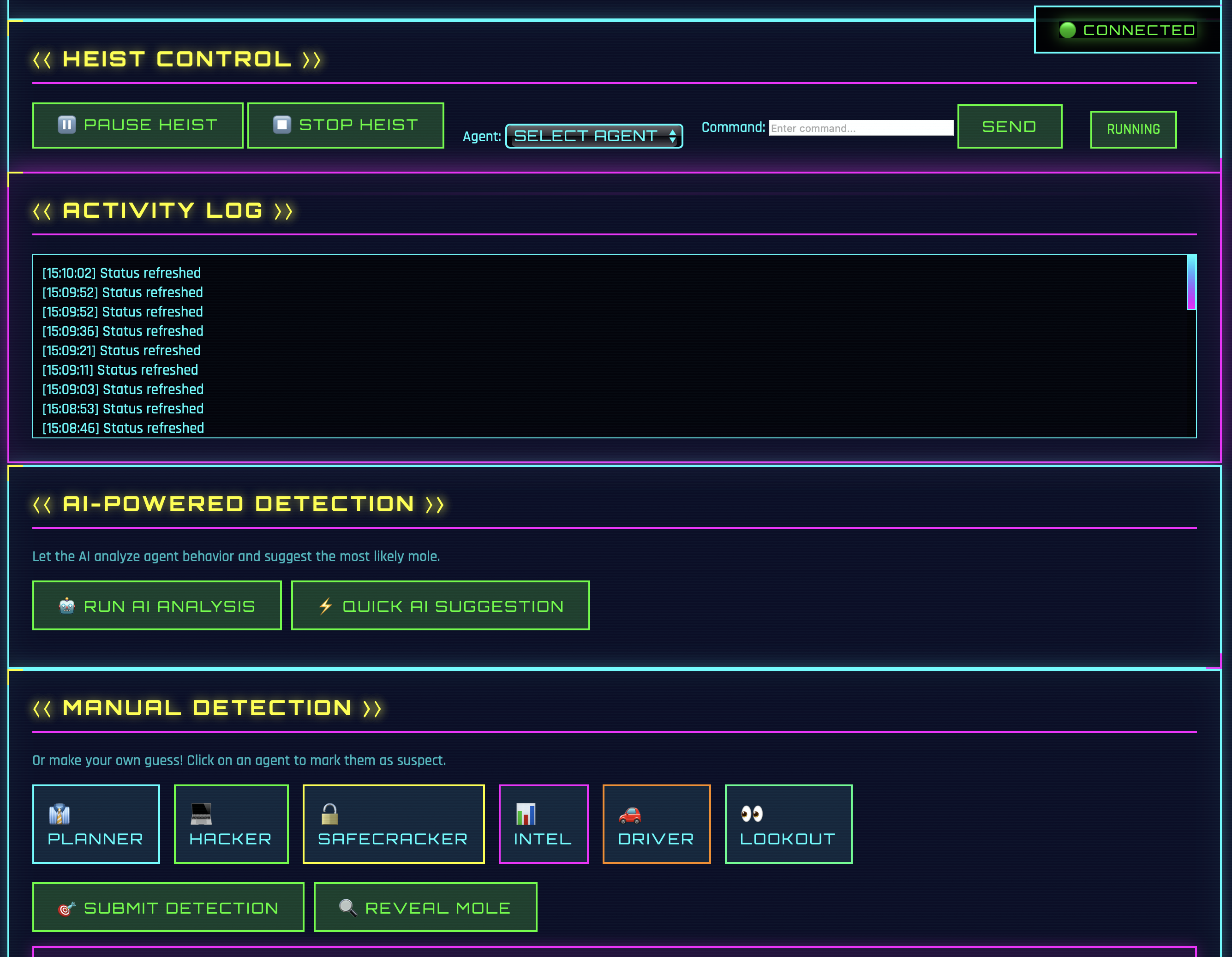
Alternatively, a session can also be analyzed via the API.
curl -X POST http://localhost:8008/api/ai-detect/analyze \
-H "Content-Type: application/json" \
-d '{"session_id": "game_001"}'This call returns the complete analysis with all suspicion values and the breakdown.
For a quick suggestion, there’s a separate endpoint.
curl -X POST http://localhost:8008/api/ai-detect/suggest \
-H "Content-Type: application/json" \
-d '{"session_id": "game_001"}'This call returns only the suggestion and confidence and is therefore faster.
Summary
Day 22 makes the system intelligent. Or at least more intelligent 😅
Instead of blindly guessing, users now get well-founded AI analyses. The detection pipeline works in three steps that together form a RAG approach.
- The Retrieval part analyzes four categories with rule-based patterns: Tool Usage, Timing, Messages, and Information Quality. These analyses are measurable and reproducible. They provide structured context instead of just gut feeling. Weight: 60 percent.
- The Augmentation part prepares the context for the LLM. Top suspects are extracted, tool failures are summarized, timing mentions are counted. The LLM gets fact-based hints instead of just raw data. This prevents hallucinations.
- The Generation part uses the LLM to analyze the conversation. It understands context and nuances. It recognizes subtle sabotage patterns that rules would miss. The output is structured JSON with scores. Weight: 40 percent.
The combination makes the difference. Rules are measurable but rigid. LLMs are flexible but hallucinate. Together, 60 percent rules plus 40 percent LLM result in robust detection. Hopefully. I’ve tried it a few times now and it looks good 😉
Accuracy is significantly better than chance. With 4 agents, the baseline is 25 percent. The system typically achieves 40 to 60 percent. Not perfect, but better than guessing.
The detection API makes it easy. Session data is fetched, retrieval is performed, the LLM analyzes, and scores are combined. Done.
With Day 22, we have a real AI detective. It combines rule-based facts with LLM intelligence. And it beats chance. And tomorrow it’s back to Docker 😄