In diesem Artikel möchte auf Entscheidungsbäume eingehen. Weil es sich anbietet werden wir unter anderem auch kurz über GridSearchCV und andere benötigte Bibliotheken reden. Und das alles funktioniert- zumindest in meinem Fall - nicht ohne Python. Diesen Python-Code werden wir blockweise/zeilenweise durchgehen. Es ist auf jeden Fall von Vorteil, wenn du schon mal programmiert hast und ideal, wenn du dich mit Python auskennst.
Entscheidungsbaum
Beginnen wir mit dem Entscheidungsbaum. Entscheidungsbäume - im englischen Decision Trees - werden sowohl für Klassifikations- als auch Regressions-Aufgaben eingesetzt. In der folgenden Grafik eines Entscheidungsbaums (den wir im folgenden programmieren werden) sind die hirarchisch aufeinander folgenden Entscheidungen dargestellt. Es handelt sich dabei um einen strukturierten Prozess, um Entscheidungen zu treffen. Jeder Knoten stellt eine Entscheidung dar, jede Kante ein Ergebnis oder eine Folgeentscheidung.
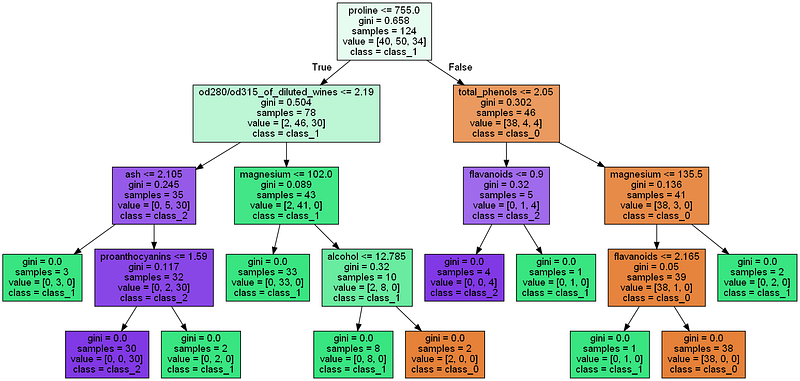 Entscheidungsbaum Wein-Datensatz - Quellcode am Ende des Beitrags, Bild vom Autor
Entscheidungsbaum Wein-Datensatz - Quellcode am Ende des Beitrags, Bild vom Autor
Bei einem Entscheidungsbaum handelt es sich um einen Algorithmus des überwachten Lernens.
Der Wein Datensatz
Steigen wir nun mit Hilfe des Wein-Datensatzes von Scikit-learn in die Programmierung eines solchen Entscheidungsbaumes ein. Zunächst müssen wir in Pyhton die nötigen Bibliotheken importieren:
import numpy as np
np.random.seed(42)
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_splitNumpyist eine Programmbibliothek, die eine einfache Handhabung von Vektoren, Matrizen und höherdimensionalen Arrays ermöglicht. Es bietet auch eine Vielzahl von Funktionen für numerische Berechnungen, die in der wissenschaftlichen Programmierung und Datenanalyse häufig verwendet werden.Pandasist eine Programmbibliothek, die die Verarbeitung und Analyse von tabellarischen Daten erleichtert. Es bietet Datenstrukturen wie Series und DataFrame, die ähnlich wie Spalten und Tabellen in relationalen Datenbanken oder Arrays in Numpy sind. Mit pandas kann man einfach Daten lesen, bearbeiten, manipulieren, modellieren und visualisieren. Es ist eines der am häufigsten verwendeten Werkzeuge in der Datenanalyse und -vorbereitung.- Der Wein-Datensatz (
load_wine) ist ein Beispieldatensatz, der in der Python-Bibliothek Scikit-learn enthalten ist. Er enthält Informationen über verschiedene Weine, wie z.B. Alkoholgehalt, Säure, Farbpigmente und Proanthocyanidine. Der Datensatz besteht aus 178 Proben von Weinen und 13 Merkmalen. Dieser Datensatz wird häufig in Beispielen verwendet, um die Verwendung von Scikit-learn für die Klassifizierung von Problemen zu demonstrieren. - Der
DecisionTreeClassifierist ein Klassifikationsmodell aus der Bibliothek Scikit-learn, das auf dem Konzept des Entscheidungsbaums basiert. Der DecisionTreeClassifier erstellt einen Entscheidungsbaum aus den gegebenen Trainingsdaten und verwendet ihn dann, um neue Eingabedaten zu klassifizieren. Dieses Modell ist besonders nützlich bei der Identifizierung von Mustern und Beziehungen in komplexen, multidimensionalen Datensätzen. Es ist einfach zu verstehen und zu interpretieren, und es ist auch robust gegenüber Veränderungen in den Daten. GridSearchCVist eine Methode, die es ermöglicht, eine Vielzahl von Hyperparametern für einen bestimmten Algorithmus auszuprobieren und die besten Parameter automatisch auszuwählen. GridSearchCV führt eine Suche über einen angegebenen Parameterbereich durch und schätzt die Leistung des Algorithmus anhand einer angegebenen Bewertungsfunktion. Es ermöglicht es, die besten Hyperparameter für ein Modell schnell und einfach zu finden, ohne dass man jeden Wert manuell ausprobieren muss.train_test_splitist eine Funktion, die verwendet wird, um einen Datensatz in Trainings- und Testdaten aufzuteilen. Es nimmt als Eingabe den Datensatz und die Zielvariablen und teilt sie in zwei Teile auf: Einen Teil für das Training des Modells und einen Teil für die Bewertung der Leistung des Modells.
Im nächsten Code-Block wird zunächst der Wein-Datensatz geladen und dann werden die Features data und die Beobachtungsgrößen target des Wein-Datensatzes x und y zugewiesen. Das erspart uns im weiteren Verlauf einfach ein paar Tastenanschläge und x sowie y sind gängige Bezeichnungen für eben jene Daten.
dataset = load_wine()
x, y = dataset.data, dataset.targetDanach übernehmen wir die Daten in ein Pandas DataFrame und weisen den Spalten dataset.feature_names (die Feature-Namen) sowie y (die Beobachstungsgröße) zu.
df = pd.DataFrame(x, columns = dataset.feature_names)
df["y"] = y
df.head()Mit df.head() kann man sich nun die ersten 5 Zeilen des DataFrames anzeigen lassen und sich das Datenset genauer ansehen.
 df-head() unseres DataFrames, Bild vom Autor
df-head() unseres DataFrames, Bild vom Autor
Eines der Features ist zum Beispiel der Alkohol-Gehalt in der ersten Spalte. In Spalte y hingegen ist die zu erlernende Klasse (, oder ) hinterlegt. Wer mehr über die Features und den Datensatz erfahren möchte, sollte unter diesem Link zur Scikit-learn-Dokumentation fündig werden.
Sobald unser DataFrame erstellt ist und wir unsere Daten in x und y aufgeteilt haben, erstellen wir Trainings- und Testdatensatz.
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = 0.3, random_state=42)Die obere Zeile wird genutzt, um den Datensatz bestehend aus x und y in durch einen Seed (hier random_state = 42) zufällig verteilte Trainings- und Testdatensätze aufzuteilen. Durch test_size = 0.3 wird definiert, dass in diesem Fall der Testdatensatz des ursprünglichen Wein-Datensatzes enthalten soll.
- Ein Seed (engl. für Saat) bezieht sich auf den Startwert, der verwendet wird, um einen Zufallszahlengenerator zu initialisieren. Dieser Startwert bestimmt die erste Zufallszahl, die der Generator erzeugt und die folgenden Zufallszahlen werden durch einen deterministischen Algorithmus berechnet, der auf dem Seed basiert. Verwendet man den gleichen Seed bei mehreren Durchläufen, generiert der Zufallszahlengenerator die gleiche Reihe von Zufallszahlen. Das kann von Vorteil sein, um die Reproduzierbarkeit von Experimenten sicherzustellen, oder um die Ergebnisse von Simulationen zu vergleichen.
Im nächsten Codeblock werden die Hyperparameter criterion, max_depth, min_samples_split, min_samples_leaf und max_features für die GridSearchCV angegeben.
parameters = {
'criterion': ['gini', 'entropy'],
'max_depth': [None, 2, 4, 8, 10],
'min_samples_split': [1, 2, 4], # Wie viele Samples müssen noch in diesen Split gehen, um diesen zu erstellen?
'min_samples_leaf': [1, 2],
'max_features': ['auto', 'sqrt', 'log2']
}criteriongibt an, welche Bewertungsfunktion verwendet werden soll, um die Leistung der verschiedenen Modelle, die durch die GridSearchCV getestet werden, zu bewerten. Beispiele für mögliche Criteria sind die Genauigkeit, die logarithmische Verlustfunktion oder der F1-Score. Durch die Auswahl des richtigen Kriteriums kann man sicherstellen, dass das Modell auf die spezifischen Anforderungen des Problems angepasst wird.max_depthlegt die maximale Tiefe des Baums fest. Er wird verwendet, um die optimale Tiefe des Baums zu finden, indem verschiedene Werte ausprobiert und die besten Ergebnisse ausgewählt werden. Eine höheremax_depthführt zu komplexeren und möglicherweise anpassungsfähigeren Modellen, aber auch zu einem höheren Risiko von Überanpassung.min_samples_splitwird verwendet, um zu bestimmen, wie viele Proben mindestens in einem Knoten vorhanden sein müssen, bevor eine Trennung durchgeführt werden kann. Ein höherer Wert führt dazu, dass der Baum tiefer wird und möglicherweise überanpassen verhindert. Ein niedrigerer Wert kann jedoch dazu führen, dass der Baum zu oberflächlich wird und möglicherweise nicht in der Lage ist, die relevanten Mustererkennungen zu erfassen.min_samples_leafwird verhindert, um die Anzahl der Proben pro Blatt im Entscheidungsbaum zu bestimmen. Ein höherer Wert führt dazu, dass die Blätter im Baum weniger empfindlich auf kleine Veränderungen in den Daten reagieren und somit überanpassen verhindert. Ein niedriger Wert kann jedoch dazu führen, dass der Baum zu überanpassen anfällig wird und möglicherweise nicht in der Lage ist, die relevanten Mustererkennungen zu erfassen.max_featureswird verwendet, um die Anzahl der Merkmale zu bestimmen, die bei jedem Split betrachtet werden sollen. Es gibt drei Möglichkeiten, wie der Wert festgelegt werden kann: als absoluter Wert (bspw. max_features = 4), als Bruchteil der verfügbaren Merkmale (bspw.max_features = 0.8) oder als logarithmischer Bruchteil der verfügbaren Merkmale (bspw.max_features = log2). Ein höherer Wert führt dazu, dass der Baum mehr Merkmale betrachtet, was ihm ermöglicht, komplexere Mustererkennungen zu erfassen, kann aber auch zu überanpassen führen. Ein niedriger Wert kann dazu führen, dass der Baum nicht in der Lage ist, die relevanten Mustererkennungen zu erfassen.
Wer mehr über GridSearchCV erfahren möchte sollte sich die Scikit-Learn Dokumentation durchlesen. Nun erstellen wir endlich eine Instanz des DecisionTreeClassifiers bzw. unseren ersten Entscheidungsbaum und initialisieren die GridSearchCV bevor wir sie durchführen. Je nach Leistung eures Rechners kann der Vorgang länger dauern.
clf = DecisionTreeClassifier()
grid_cv = GridSearchCV(clf, parameters, cv = 10, n_jobs = -1)
grid_cv.fit(x_train, y_train)Die GridSearchCV probiert nun jede Kombination der oben definierten Parameter und ermittelt mit Hilfe des Scores die beste Kombination von Hyperparametern. cv = 10 bedeutet, dass unser Datensatz in zehn gleich große Teile (Folds) aufgeteilt wird. Das Modell wird dann an neun Teilen trainiert und am zehten Teil validiert. Dieser Vorgang wird zehn Mal wiederholt, wobei sich jedes Mal der Teil zum Validieren ändert. Durch n_jobs = -1, erlaubt die Nutzung aller CPUs und beschleunigt so das Verfahren. Nach dem Training (fit) lassen wir uns eben diese Hyperparameter ausgeben.
print(f"Parameters of best model: {grid_cv.best_params_}")
print(f"Score of best model: {grid_cv.best_score_}")Das Ergebnis der GridSearchCV Suche. Der Score beschreibt die Leistung des Modells:
Parameters of best model: {'criterion': 'gini', 'max_depth': 10, 'max_features': 'sqrt', 'min_samples_leaf': 2, 'min_samples_split': 4}
Score of best model: 0.9512820512820512
Diese Parameter übernehmen wir in unseren Entscheidungsbaum und lassen diesen trainieren.
clf = DecisionTreeClassifier(
criterion='gini',
max_depth=10,
max_features='sqrt',
min_samples_leaf=2,
min_samples_split=4)
clf.fit(x_train, y_train)Während dieses iterativen Vorgangs wird unser Entscheidungsbaum immer wieder angepasst und verbessert. Nachdem wir unser Training beendet haben können wir Leistung unseres Baumes an den Test-Daten testen.
score = clf.score(x_test, y_test)
print(f"Accuracy: {score}")Accuracy: 0.8888888888888888
Der Score eines Entscheidungsbaums bezieht sich auf die Leistung des Modells, gemessen anhand einer bestimmten Metrik. Die häufigste Metrik, die verwendet wird, um die Leistung eines Entscheidungsbaum zu messen, ist die Genauigkeit (Accuracy). Sie gibt an, wie oft das Modell die richtige Klasse für ein gegebenes Beispiel vorhergesagt hat. Es berechnet sich als die Anzahl der korrekt klassifizierten Beispiele geteilt durch die Gesamtzahl der Beispiele. Es ist wichtig zu beachten, dass die Genauigkeit allein nicht immer ein ausreichendes Maß für die Leistung eines Entscheidungsbaums ist, insbesondere wenn die Klassen im Datensatz ungleich verteilt sind oder wenn das Modell in der Lage sein muss, bestimmte Arten von Fehlern zu minimieren. In solchen Fällen können andere Metriken, wie z.B. Precision, Recall oder F1-Score, sinnvoller sein.
Unser Entscheidungsbaum lässt sich auch grafisch darstellen. Mit den folgenden Zeilen werden die dafür benötigten Bibliotheken importiert und letztlich der Entscheidungsbaum mit den Entscheidungen etc. abgebildet.
from sklearn import tree
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=dataset.feature_names,
class_names=dataset.target_names,
filled=True)
graph = graphviz.Source(dot_data, format="png")
graphDie obigen Zeilen liefern den Entscheidungsbaum am Anfang dieses Beitrags. Wenn du dazu noch Fragen hast, melde dich gerne bei mir.
Zusammenfassung
An dieser Stelle haben wir also nun unseren ersten Datensatz verwendet und unseren ersten Entscheidungsbaum programmiert. Wir haben uns auch angeschaut, was zum Beispiel die GridSearchCV macht und warum sie so nützlich für uns sein kann.
Im nächsten Artikel beschreibe ich dir, was ein Random Forrest ist und wie man diesen programmiert.