Aus dem letzten Artikel wissen wir, dass im Grunde alle gängigen Verfahren der künstlichen Intelligenz als schwache KI einzuordnen sind. Und diese Verfahren und Methoden lassen sich noch weiter unterteilen. Dieser Unterteilung wollen wir uns heute widmen.
Tatsächlich befassen wir uns, wenn ich von künstlicher Intelligenz rede, mit dem Machine Learning (ML) — einer Kategorie künstlicher Intelligenz. ML lässt sich weiter unterteilen in Supervised, Unsupervised und Reinforcement Learning. Mit diesen dreien und ihren jeweiligen Unterkategorien beschäftigten wir uns heute.

Source Researchgate
Wie auch zuvor sind die Themen deutlich umfangreicher. Ich versuche sie stark vereinfacht darzustellen. Ein Großteil der unten aufgeführten Algorithmen wird in späteren Artikel noch näher beschrieben.
Supervised Learning
Im Supervised Learning bzw. dem überwachten Lernen, müssen dem ML Algorithmus labeled Data bzw. gekennzeichnete Daten zur Verfügung gestellt werden. Durch die sogenannten Features (Eingangsdaten des Modells) und die hiermit verknüpften Zielwerte oder Beobachtungsgrößen (Ausgangsdaten des Modells) werden während des Trainings konkrete Zusammenhänge erlernt und mithilfe dieser Zusammenhänge oder dieses Modells anschließend während der Tests oder Validierungen Vorhersagen für neue Eingangsdaten gemacht. Dieses Verfahren erfordert eine gute und große Datenbasis, um die notwendigen Zusammenhänge zu erlernen und präzise Vorhersagen treffen zu können. Das ist mit einem hohen menschlichen Aufwand verbunden und nicht für alle Datensets möglich. Wie hoch dieser Aufwand ist, lässt sich an den folgenden Beispielen für die Klassifikation erahnen.
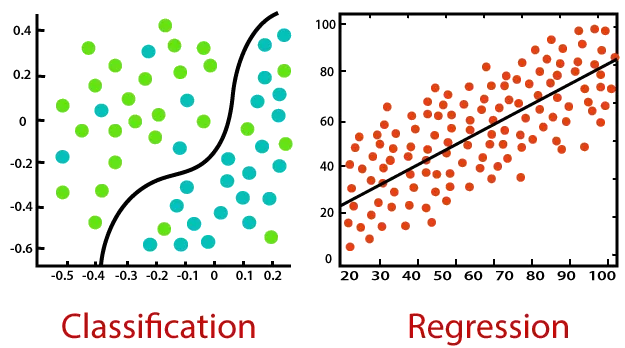
Klassifikation
Bei der Klassifikation werden Modelle trainiert, welche die Eingangsdaten in feste Kategorien einteilen. Ein Beispiel, welches wir in einem späteren Artikel auch mit Python-Code bearbeiten, ist die öffentlich verfügbare MNIST-Datenbank, welche aus 60.000 Beispielen im Trainings- und 10.000 Beispielen im Testdatenset besteht. Dabei handelt es sich um handgeschriebene Ziffern, die in 28x28 Pixel großen Bildern in Graustufen abgespeichert sind. Jedes Bild ist wiederum mit einem eindeutigen Label bzw. einer eindeutigen Beobachtungsgröße verknüpft.

MNIST dataset, image from Wikipedia
Der Trainingsdatensatz wird nun genutzt, um das Modell — häufig ein sogenanntes Convolutional Neural Network — zu trainieren und der Testdatensatz, um das Modell zu testen und validieren. Zu dem Zweck wird jedes Bild in das Modell gegeben, welches eine Prädiktion (einteilen in eine der zehn Kategorien/Ziffern) macht. Während des Trainings wird das Modell stets aktualisiert, um diese Prädiktion zu verbessern. Auch diesen Vorgang werden wir uns noch in Python-Code im konkreten Beispiel genauer anschauen.
Weitere Beispiele sind:
- Fashion-MNIST - eine Datenbank mit Bildern von Kleidungsstücken aus ebenfalls zehn Kategorien
- food101 - eine Datenbank mit Bildern von Essen aufgeteilt in 101 Kategorien
- Cats vs. Dogs - eine Datenbank mit Bildern von Hunden und Katzen und folglich zwei Kategorien
Besonders häufig werden die folgenden Algorithmen eingesetzt:
- Logistische Regression
- K-nearest neighbors (KNN)
- Support Vector Machines (SVM)
- Naive Bayes
- Entscheidungsbäume (Decision Trees) und abgeleitete Verfahren wie Random Forrests oder Gradient Boosted Trees
- Künstliche neuronale Netze (zum Beispiel Convolutional Neural Networks)
Regression
Die Regression wird häufig genutzt, um Trends zu erkennen oder gezielte Vorhersagen zu treffen. Eingangsdaten sind zum Beispiel Alter, Gehalt oder Preise, wodurch das Modell Zusammenhänge erlernt und Vorhersagen trifft. Ein oft genanntes Beispiel ist das Boston Housing Dataset. Auch diesen Datensatz werden wir in einem kommenden Artikel bearbeiten und ein Modell trainieren.

Boston skyline, image from Pixabay
Beim Boston Housing Datensatz handelt es sich um einen realen Datensatz, welcher in den 1970er Jahren erhoben wurde und neben den Hauspreisen 14 Features bzw. Merkmale zum Hauspreis von Häusern in Boston enthält. Im Datensatz sind 506 Einträge enthalten. Mit diesem Datensatz kann man ein Modell trainieren, welches anhand der Features (bspw. Kriminalitätsrate, Anzahl der Räume, …) die Preise vorhersagen bzw. schätzen kann. Anders als bei der Klassifikation — bei der eine definierte Anzahl von Kategorien die Ausgangsgröße des Modells bestimmt — kann ein Regression-Algorithmus einen beliebigen Ausgangswert liefern.
Besonders häufig werden für die Regression die folgenden Algorithmen eingesetzt:
- Lineare Regression
- Künstliche neuronale Netze
- Entscheidungsbäume (Decision Trees) und abgeleitete Verfahren wie Random Forrests oder Gradient Boosted Trees
Unsupervised Learning
Anders als beim überwachten Lernen, werden beim unüberwachten Lernen keine gekennzeichneten Daten benötigt. Der Algorithmus versucht in den Daten Muster und Strukturen zu erkennen. Diese Muster können nur mithilfe der Features selbst erkannt werden, weil es keine Beobachtungsgrößen gibt bzw. die Daten nicht gekennzeichnet sind.
Um Datensätze für das Unsupervised Learning zu generieren, sind daher keine großen menschlichen Aufwände notwendig, weil die Einträge nicht gekennzeichnet werden müssen.
Clustering / Segmentierung
Das Clustering bzw. die Segmentierung wird genutzt, um Dateneinträge in gleichen Gruppen zu sortieren und gilt als die wichtigste Methode des Unsupervised Learnings. Beim Clustering werden die Daten so gruppiert, dass Einträge mit gleichen oder ähnlichen Eigenschaften einer Gruppe zugeordnet werden.
Häufig wird für diese Einteilung der K-Means Algorithmus eingesetzt, wobei k die Anzahl von Clustern beschreibt.
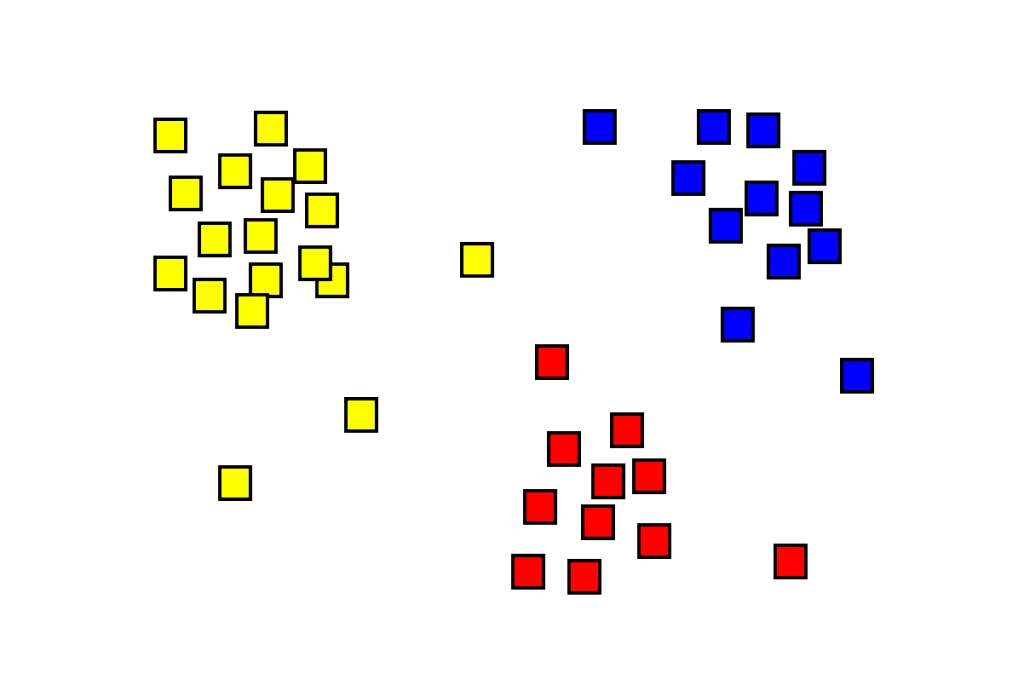
Cluster analysis with k = 3, image from Wikipedia
Außerdem gibt es noch das hierarchische Clustern, das Density-Based Spatial Clustering of Applications with Noise (DBSCAN) oder Gaussian Mixture Models (GMM).
Dimensionsreduktion (Dimensionality Reduction) / Komprimierung
Die Dimensionsreduktion erfüllt die Aufgabe, die Anzahl der Features des Datensatzes auf die wesentlichen und zielführenden Features zu reduzieren. Diese Methode wird häufig eingesetzt, um das sogenannte Overfitting zu reduzieren. Beim Overfitting lernt das Modell (zu) spezifisch anhand des Trainingsdatensatzes und ist anschließend nicht in der Lage eine gute Prädiktion für weitere Daten zu machen. Durch die Reduktion der Feature-Anzahl muss das Modell genereller lernen und die Wahrscheinlichkeit des Overfittings sinkt.
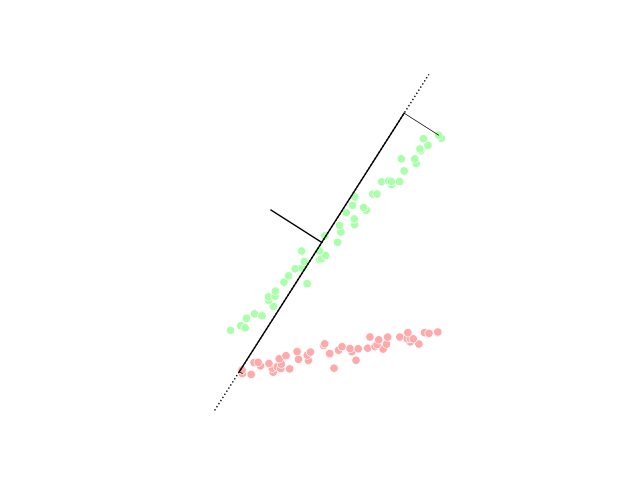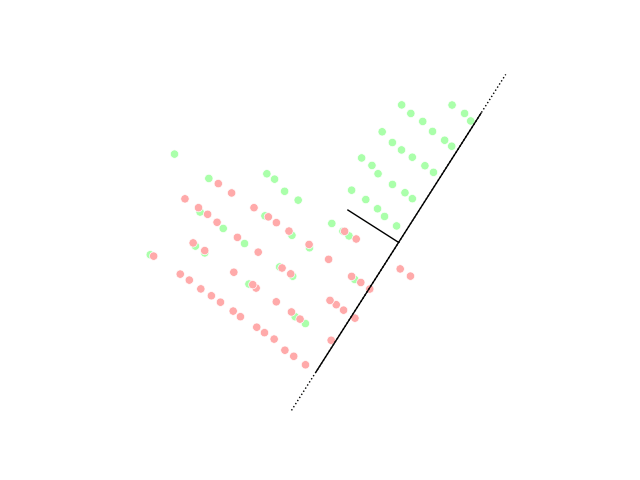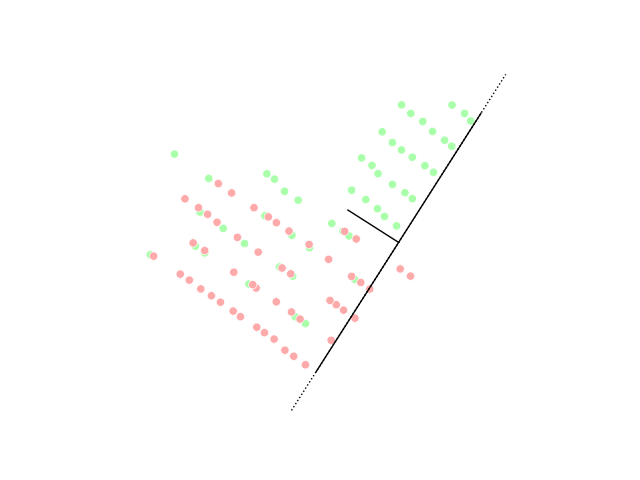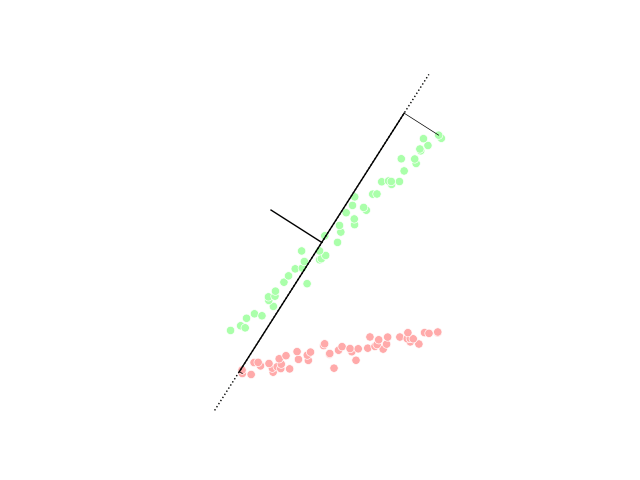 PCA visualization, image from Wikipedia
PCA visualization, image from Wikipedia
Häufig verwendet werden auch die folgenden Verfahren:
- PCA - Principal Components Analysis
- KNN - K-Nearest-Neighbours
- NMF - Non Negative Matrix Factorization
Reinforcement Learning
Neben dem Supervised und dem Unsupervised Learning gibt es noch das Reinforcement Learning. Auch das Reinforcement Learning muss ohne gekennzeichneter Datensätze — also ohne Beobachtungsgrößen — auskommen. Stattdessen lernt der Reinforcement Learning Algorithmus durch Interaktion mit der Umgebung.
Reinforcement learning principle, image from researchgate
Am Beispiel von Breakout möchte ich versuchen das Prinzip von Reinforcement Learning zu beschreiben. Der eine oder andere wird das Spiel für Atari noch kennen: Man versucht durch Bewegung des Balkens nach links und nach rechts den Ball zurück zu lenken und die regenbogenfarbige Wand im oberen Bildschirmdrittel zu zerstören. Für letzteres erhält man Punkte. Gelingt es nicht, den Ball zurückzuspielen, ist das Spiel verloren.

Beim Reinforcement Learning gibt man dem Algorithmus die möglichen Aktionen (Starten des Spiels, nichts tun, Balken nach links, Balken nach rechts) mit und belohnt ihn für jede gute Aktion bzw. bestraft ihn für schlechte Aktionen, zum Beispiel für das Verlieren des Spiels. Diese Sammlung von Belohnungen (Rewards) und Bestrafungen, die sogenannte Policy, sorgt dafür, dass der zunächst dumme Algorithmus erlernt, was er (der Agent) machen muss, um die Punktzahl zu erhöhen oder das Spiel zu gewinnen. Das Spiel selber ist das sogenannte Environment oder die Umgebung, mit der der Agent interagiert, um die Punkte zu sammeln. Der Agent erlernt auf diese Weise, wie das Spiel funktioniert und erlernt sogar ganze Strategien. Doch dazu ein anderes Mal mehr.
Auch hier gilt wieder: Ich habe es sehr stark vereinfacht, um eine Übersicht zu erstellen. Eine detailliertere Beschreibung mit Python-Code werde ich in einem späteren Artikel zur Verfügung stellen.