Die Transformer-Architektur - Grundlagen und Anwendungen
In diesem und dem folgenden Artikel möchte ich ein grundlegendes Verständnis der Transformer-Architektur und ihrer Anwendung in mehr oder weniger modernen Sprachmodellen erarbeiten. Im Fokus soll dabei der Aufmerksamkeitsmechanismus stehen, der letztlich die Kernkomponente dieser Architektur ist.
Ein Paper was ich dazu gelesen habe, ist zwar aus 2023 und damit für viele sicher ein alter Hut, aber ich habe mich damit noch nicht näher auseinander gesetzt: Attention is All You Need.
Zu Beginn werde ich anhand eines praktischen Beispiels mit dem Modell DistilGPT-2 die Generierung von Textsequenzen demonstrieren. Dieser Einstieg soll der Veranschaulichung der grundlegenden Funktionsweise und Herausforderungen bei der statistischen Textgenerierung dienen. Im Anschluss gehe ich auf die Konzepte von Token und Embeddings ein und versuche diese näher zu erläutern, da sie für die Verarbeitung von Sprache durch GPTs essenziell sind.
Darauf aufbauend versuche ich den Aufmerksamkeitsmechanismus im Detail zu erklären, sowohl mit Hilfe theoretischer Grundlagen als auch mit praktischen Beispielen zur Visualisierung der Aufmerksamkeitsmuster. Ziel ist es die Funktionsweise und die Bedeutung des Mechanismus in Texten zu verdeutlichen.
Fangen wir am besten vorne an …
DistilGPT-2
Was ist DistilGPT-2?
DistilGPT-2 ist eine komprimierte und effizientere Version des bekannten Sprachmodells GPT-2. Es wurde speziell entwickelt, um die Modellgröße und den Rechenaufwand zu reduzieren. Das macht es ideal für den Einsatz auf ressourcenschonenden Geräten wie mobilen Endgeräten oder eingebetteten Systemen.
Diese Reduzierung wurde durch den sogenannten Knowledge Distillation-Prozess erreicht. Hierbei handelt es sich um ein Trainingsverfahren, das Wissen und Fähigkeiten von einem größeren Modell (in diesem Fall GPT-2) auf ein kleineres Modell überträgt. Dies führt zu einer geringeren Parameteranzahl, was wiederum den Speicherplatzbedarf und die Anforderungen an die Rechenleistung senkt. Dadurch eignet sich DistilGPT-2 hervorragend für Demonstrationszwecke: Du kannst die Grundlagen einfach erklären und visualisieren, ohne auf einen besonders starken Rechner angewiesen zu sein; dein handelsüblicher Laptop reicht völlig aus, um mit dem Modell zu experimentieren.
Natürlich bringt diese Komprimierung auch Nachteile mit sich. Es ist möglich, dass das Modell bei komplexen Aufgaben an Genauigkeit einbüßt. Auch die Fähigkeit, lange und kohärente Texte zu erzeugen, ist eingeschränkt, ebenso wie die sprachliche Vielfalt. Für die hier gezeigten Anwendungen ist das jedoch ein hinnehmbarer Kompromiss.
Tokens und Embeddings - Die Bausteine
Das folgende ist eine kurze Einführung in die Bausteine von Sprachmodellen. Ausführlichere Informationen findest du unter Tokenisierung und Embeddings and similarity metrics.
Tokens und Tokenisierung
Tokens sind die grundlegenden Einheiten, in die ein Sprachmodell Text zerlegt. Dieser Prozess wird Tokenisierung genannt. Stellen wir uns das an einem konkreten Beispiel vor. Wir verwenden dazu den distilgpt2-Tokenizer.
Wir importieren unsere Abhängigkeiten und laden dann das distilgpt2-Modell und den zugehörigen Tokenizer. Der Tokenizer ist ein wesentlicher Bestandteil, da er den Eingabetext in die numerische Darstellung (Token-IDs) umwandelt, mit der das Modell arbeiten kann.
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("distilgpt2")
model = GPT2LMHeadModel.from_pretrained("distilgpt2")Nun definieren wir unseren Beispielsatz. Dieser Satz wird vom Tokenizer in eine Sequenz von Token-IDs umgewandelt. Diese IDs sind die numerische Darstellung des Eingabetextes, auf deren Basis das Modell die entsprechenden Embeddings abruft.
input_sentence = "May the force be with you."
tokens = tokenizer.tokenize(input_sentence)
token_ids = tokenizer.encode(input_sentence)
print(f"Eingabesatz: {input_sentence}")
print(f"Tokens: {tokens}")
print(f"Token-IDs: {token_ids}")Die Ausgabe zeigt:
Eingabesatz: May the force be with you.
Tokens: ['May', 'Ġthe', 'Ġforce', 'Ġbe', 'Ġwith', 'Ġyou', '.']
Token-IDs: [6747, 262, 2700, 307, 351, 345, 13]Wie du siehst, zerlegt der Tokenizer den Satz in eine Liste von Tokens. Beachte das Präfix Ġ, das ein Leerzeichen vor dem jeweiligen Wort anzeigt. Das ist wichtig, da Tokenizer nicht immer ganze Wörter verwenden, sondern auch Teilwörter oder sogar einzelne Zeichen. Für jedes Token wird dann eine eindeutige Token-ID generiert, die eine numerische Darstellung des Tokens ist. Diese IDs sind es, die das Sprachmodell intern verarbeitet.
Embeddings
Nach der Tokenisierung kommen die Embeddings ins Spiel. Vereinfacht ausgedrückt sind Embeddings numerische Vektordarstellungen von Tokens, die deren semantische Bedeutung erfassen. Stell dir vor, jedes Wort wird in einem mehrdimensionalen Raum als Punkt dargestellt. Wörter mit ähnlicher Bedeutung liegen näher beieinander, während Wörter mit unterschiedlicher Bedeutung weiter auseinander liegen.
Diese komplexen Vektoren werden während des Trainings von Sprachmodellen gelernt. Um die Ähnlichkeit zwischen diesen Vektoren zu messen, werden verschiedene Metriken verwendet, die bekannteste davon ist die Kosinus-Ähnlichkeit.
Warum Kosinus-Ähnlichkeit?
Im Gegensatz zu Distanzmaßen wie der Euklidischen Distanz, die den geraden oder direkten Abstand zwischen zwei Punkten messen und stark von der Länge der Vektoren beeinflusst werden, misst die Kosinus-Ähnlichkeit den Winkel zwischen zwei Vektoren. Ein kleiner Winkel (Kosinus-Wert nahe 1) bedeutet, dass die Vektoren in eine sehr ähnliche Richtung zeigen, also eine hohe semantische Ähnlichkeit besteht. Ein großer Winkel (Kosinus-Wert nahe 0 oder negativ) deutet auf geringe oder keine semantische Ähnlichkeit hin.
Dies macht die Kosinus-Ähnlichkeit besonders geeignet für Sprachmodelle, da sie die inhaltliche Verwandtschaft von Wörtern unabhängig von der Stärke ihrer Vektordarstellung (ihrer Länge) effektiv erfasst.
Zusammenfassung
Tokens sind die zerlegten Textbausteine, die von Sprachmodellen verarbeitet werden. Ihnen werden Token-IDs zugewiesen. Embeddings sind die numerischen Vektordarstellungen dieser Tokens, die ihre semantische Bedeutung einfangen. Um die Ähnlichkeit zwischen Wörtern zu messen, wird oft die Kosinus-Ähnlichkeit verwendet, da sie die inhaltliche Nähe der Embeddings effektiv widerspiegelt. Diese Konzepte sind fundamental für das Verständnis, wie moderne Sprachmodelle Text verarbeiten und verstehen.
Generierung ganzer Sätze
Nachdem wir die grundlegenden Konzepte von Tokens und Embeddings verstanden haben, schauen wir uns an, wie diese Bausteine genutzt werden, um Text zu generieren. Im Kern funktioniert das so: Ein Sprachmodell nimmt einen Eingabesatz und versucht, das wahrscheinlichste nächste Wort vorherzusagen. Dieses Wort wird dann an den Satz angehängt, und der Prozess wiederholt sich. Mit jedem neuen Wort wird der Eingabesatz länger, und die Vorhersagen des Modells passen sich an den erweiterten Kontext an.
Zunächst definieren wir eine Funktion, die uns die Top-N-Wortvorhersagen zurückgibt:
def get_top_n_predictions(model, tokenizer, input_ids, n=10):
with torch.no_grad():
outputs = model(input_ids)
predictions = outputs.logits
next_word_probabilities = predictions[0, -1, :]
top_n_values, top_n_indices = torch.topk(next_word_probabilities, n)
top_n_predictions = []
for i in range(n):
predicted_token = tokenizer.decode([top_n_indices[i]])
top_n_predictions.append((predicted_token, top_n_values[i].item()))
return top_n_predictionsDiese Funktion nimmt das Modell, den Tokenizer und die Token-IDs als Eingabe und gibt eine Liste von Top-Wörtern und ihren Logits zurück. Logits sind die rohen, unnormalisierten Vorhersagewerte des Modells, die noch nicht in Wahrscheinlichkeiten umgewandelt wurden (dafür wäre eine Softmax Activationfunction-Funktion nötig).
Nun lassen wir uns überraschen, was das Modell aus unseren ersten Worten macht. Das folgende Beispiel demonstriert diesen iterativen Prozess, indem das Modell schrittweise die nächsten drei wahrscheinlichsten Tokens voraussagt und das wahrscheinlichste davon an den Satz anhängt. Wir wiederholen diesen Vorgang zehn Mal.
input_sentence = "May the force be"
for _ in range(0, 10):
input_sentence = input_sentence + top_predictions[0][0]
print(input_sentence)
input_ids = tokenizer.encode(input_sentence, return_tensors="pt")
top_predictions = get_top_n_predictions(model, tokenizer, input_ids, n=3)
for token, probability in top_predictions:
print(f"- '{token}': {probability:.4f}")Die Ausgabe:
May the force be on
- ' on': -64.0309
- ' in': -64.0530
- 'fitting': -64.3531
May the force be on the
- ' the': -46.4960
- ' its': -47.9148
- ' a': -48.4800
May the force be on the right
- ' right': -61.6658
- ' side': -61.7417
- ' ground': -61.7950
May the force be on the right side
- ' side': -57.5233
- ' track': -58.6298
- '.': -59.0986
May the force be on the right side of
- ' of': -36.5692
- '.': -38.0388
- ',': -38.4764
May the force be on the right side of the
- ' the': -45.2770
- ' this': -47.7126
- ' a': -47.7725
May the force be on the right side of the border
- ' border': -50.3143
- ' line': -50.3288
- ' road': -50.4293
May the force be on the right side of the border.
- '.': -57.7002
- ',': -58.0834
- ' and': -58.8902
May the force be on the right side of the border.�
- '�': -54.9925
- '
': -55.5651
- '<|endoftext|>': -56.4597
May the force be on the right side of the border.�
- '
': -41.7617
- '<|endoftext|>': -42.0991
- ' The': -44.4527Die Ausgabe zeigt, wie der Satz mit jeder Iteration länger wird und welche Worte als die wahrscheinlich nächsten ausgegeben werden. Bei dieser rein statistischen Methode kann es zu repetitiven und sinnlosen Texten kommen, sodass das Modell irgendwann den Kontext verlieren könnte. Und tatsächlich ist es so, dass gegen Ende keine einfachen Buchstaben mehr, sondern z.B. ” (ein Leerzeichen, das vom Tokenizer oft so dargestellt wird) oder gar ein Zeilenumbruch angehängt werden.
Und natürlich wurden wir alle enttäuscht, hatten wir doch mit einem anderen Ergebnis für unseren Beispielsatz gerechnet!
Aufmerksamkeitsmechanismus - Herzstück der Transformer
Grenzen sequentieller Modelle
Vor der Einführung der Transformer-Architektur, auf die ich gleich näher eingehen werde, wurden hauptsächlich sequentielle Modelle wie Recurrent Neural Networks (RNNs) verwendet. Diese Modelle waren zwar in bestimmten Bereichen erfolgreich, stießen jedoch bei komplexeren Sprachaufgaben an ihre Grenzen. Zu ihren wesentlichen Einschränkungen gehörten:
- Sequentielle Verarbeitung: RNNs verarbeiten Daten nacheinander, was bei langen Sequenzen ineffizient ist. Ihr “Gedächtnis” verblasst mit zunehmender Distanz, wodurch frühe Informationen in längeren Texten verloren gehen können (das sogenannte Langzeitgedächtnisproblem).
- Verschwindende und explodierende Gradienten: Während des Trainings können Gradienten extrem klein (verschwindend) oder extrem groß (explodierend) werden. Dies behindert das Lernen von Abhängigkeiten über lange Distanzen und erschwert die effektive Aktualisierung der Modellgewichte.
- Begrenztes Kontextfenster: RNNs erfassen den Kontext über lange Sequenzen schlecht. Sie können Informationen nur schrittweise über aufeinanderfolgende Zeitschritte weitergeben, was die Generierung zusammenhängender und kontextuell präziser Texte erheblich erschwert.
- Schwierigkeiten bei der parallelen Verarbeitung: Die sequenzielle Natur von RNNs verhindert eine effiziente Parallelisierung der Berechnungen. Dies ist bei großen Datenmengen und für das Training sehr großer Sprachmodelle, die Milliarden von Parametern umfassen können, ein erheblicher Nachteil.
Diese Einschränkungen beeinträchtigen die Leistung von Sprachmodellen so massiv, dass die Transformer-Architekturen entwickelt wurden.
Ein Transformer Block
Wir nähern uns nun dem Kern der Transformer-Architektur. Um die Funktionsweise des Aufmerksamkeitsmechanismus (auch “Attention Mechanism” genannt) zu verstehen, betrachten wir ein vereinfachtes Beispiel mit unserem bekannten Satz “May the force be with you.” Es ist wichtig zu beachten, dass dies eine starke Vereinfachung darstellt: Reale Embeddings in Modellen wie GPT-2 haben oft Dimensionen im Bereich von mehreren Tausend (z.B. 768 für distilgpt2, 12288 für größere GPT-3 Modelle), die wir hier nicht visualisieren können. Wir beschränken uns daher auf 10-dimensionale Vektoren für jedes Embedding.
Zunächst wandeln wir die Wörter des Satzes in hypothetische Embeddings um. In der Praxis werden diese Embeddings natürlich während des Trainings des Modells gelernt und sind nicht manuell definiert.
import torch
import torch.nn.functional as F
word_embeddings = {
"May": torch.tensor([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]),
"the": torch.tensor([1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1]),
"force": torch.tensor([0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 0.1, 0.2, 0.3, 0.4]),
"be": torch.tensor([0.2, 0.4, 0.6, 0.8, 1.0, 0.1, 0.3, 0.5, 0.7, 0.9]),
"with": torch.tensor([0.9, 0.7, 0.5, 0.3, 0.1, 1.0, 0.8, 0.6, 0.4, 0.2]),
"you": torch.tensor([0.3, 0.1, 0.9, 0.7, 0.5, 0.2, 1.0, 0.8, 0.6, 0.4])
}
input_sentence = ["May", "the", "force", "be", "with", "you"]
input_embeddings = torch.stack([word_embeddings[word] for word in input_sentence])
print("Eingabe-Embeddings:\n", input_embeddings)Eingabe-Embeddings:
tensor([[0.1000, 0.2000, 0.3000, 0.4000, 0.5000, 0.6000, 0.7000, 0.8000, 0.9000,
1.0000],
[1.0000, 0.9000, 0.8000, 0.7000, 0.6000, 0.5000, 0.4000, 0.3000, 0.2000,
0.1000],
[0.5000, 0.6000, 0.7000, 0.8000, 0.9000, 1.0000, 0.1000, 0.2000, 0.3000,
0.4000],
[0.2000, 0.4000, 0.6000, 0.8000, 1.0000, 0.1000, 0.3000, 0.5000, 0.7000,
0.9000],
[0.9000, 0.7000, 0.5000, 0.3000, 0.1000, 1.0000, 0.8000, 0.6000, 0.4000,
0.2000],
[0.3000, 0.1000, 0.9000, 0.7000, 0.5000, 0.2000, 1.0000, 0.8000, 0.6000,
0.4000]])Als Nächstes leiten wir die sogenannten Query (Q)-, Key (K)- und Value (V)-Vektoren ab. Diese Vektoren werden aus den Eingabe-Embeddings des Satzes erzeugt und sind entscheidend für die Berechnung der Aufmerksamkeit:
- Query (Q): Repräsentiert die “Anfrage” oder das aktuelle Wort, für das wir den Kontext erfassen möchten. Es sucht nach relevanten Informationen in anderen Wörtern.
- Keys (K): Bilden eine Menge von “Schlüsseln” der anderen Wörter im Satz. Mit ihnen wird die Query verglichen, um die Relevanz der anderen Wörter zu bestimmen.
- Values (V): Sind die “Werte” oder die eigentlichen Informationen, die von den anderen Wörtern stammen und basierend auf den Aufmerksamkeitsgewichten in den Kontext einfließen sollen.
Für unser vereinfachtes Beispiel setzen wir Query, Key und Value zunächst identisch zu den input_embeddings:
query = input_embeddings
key = input_embeddings
value = input_embeddingsIn der Praxis sind Query, Key und Value nicht identisch. Jedes Eingabe-Embedding wird stattdessen mit drei unterschiedlichen, lernbaren Gewichtungsmatrizen (, , ) multipliziert.
Diese Gewichtungsmatrizen werden während des Trainings gelernt und ermöglichen es dem Modell, verschiedene Aspekte der Wortbedeutung und des Kontextes zu erfassen. Die Q-, K- und V-Vektoren können somit unterschiedliche “Projektionen” desselben Wortes darstellen, was dem Aufmerksamkeitsmechanismus mehr Flexibilität verleiht.
Nun berechnen wir mittels calculate_attention die Aufmerksamkeitsgewichte.
def calculate_attention(query, key, value, mask=None):
scores = torch.matmul(query, key.transpose(-2, -1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attention_weights, value)
return output, attention_weightsDie Aufmerksamkeitsgewichte werden berechnet, indem zunächst das Skalarprodukt (Dot Product) zwischen den Query- und Key-Vektoren jedes Wortes im Satz berechnet wird (). Dieses Skalarprodukt quantifiziert die Ähnlichkeit oder Relevanz zwischen jedem Query-Wort und jedem Key-Wort. Optional wird dieser Wert oft noch durch die Wurzel der Dimension der Key-Vektoren skaliert, um die Stabilität des Trainings zu verbessern (sog. Scaled Dot-Product Attention).
Sollte eine Maske vorhanden sein, werden die Scores für bestimmte Verbindungen auf einen sehr kleinen negativen Wert () gesetzt. Dieser große negative Wert sorgt dafür, dass die Softmax-Funktion das entsprechende Gewicht in der Aufmerksamkeitsmatrix nahe setzt. Die Maske wird verwendet, um zu verhindern, dass das Modell auf zukünftige Wörter der Sequenz zugreift. Dies ist insbesondere in Decoder-Architekturen oder beim Training wichtig, wo das Modell Wörter sequenziell generieren soll und nur Informationen aus den bisherigen Wörtern nutzen darf.
Anschließend wird die Softmax-Funktion auf die Scores angewendet. Dies wandelt die Ähnlichkeitswerte in Wahrscheinlichkeiten um, die sich für jede Zeile zu summieren. Diese Wahrscheinlichkeiten sind die eigentlichen Aufmerksamkeitsgewichte, die angeben, wie stark jedes Wort im Satz die Bedeutung des aktuellen Wortes beeinflusst.
Zuletzt wird durch die Matrixmultiplikation der Aufmerksamkeitsgewichte mit den Value-Vektoren der Kontextvektor für jedes Wort erzeugt. Dieser Kontextvektor ist eine gewichtete Summe der Value-Vektoren aller Wörter im Satz und enthält die relevanten Informationen des gesamten Satzes, wobei die Beziehungen zwischen den Wörtern berücksichtigt werden.
kontextvektoren, aufmerksamkeitsmatrix = calculate_attention(query, key, value)
print("Kontextvektoren:", kontextvektoren)
print("Aufmerksamkeitsgewichte:", aufmerksamkeitsmatrix)Kontextvektoren: tensor([[0.3463, 0.3632, 0.5661, 0.5830, 0.5999, 0.5073, 0.6081, 0.6251, 0.6420,
0.6589],
[0.6567, 0.6127, 0.6820, 0.6381, 0.5941, 0.6257, 0.4886, 0.4447, 0.4007,
0.3567],
[0.5510, 0.5572, 0.6599, 0.6661, 0.6723, 0.6456, 0.4277, 0.4339, 0.4401,
0.4463],
[0.3734, 0.4150, 0.6252, 0.6668, 0.7084, 0.4462, 0.5038, 0.5454, 0.5870,
0.6286],
[0.6475, 0.5713, 0.6231, 0.5470, 0.4709, 0.6910, 0.6014, 0.5253, 0.4492,
0.3731],
[0.4178, 0.3792, 0.6643, 0.6257, 0.5872, 0.4614, 0.6490, 0.6104, 0.5718,
0.5333]])
Aufmerksamkeitsgewichte: tensor([[0.3388, 0.0651, 0.1020, 0.1955, 0.1128, 0.1859],
[0.0622, 0.3237, 0.2064, 0.1077, 0.1867, 0.1133],
[0.0966, 0.2044, 0.3206, 0.1515, 0.1304, 0.0966],
[0.1863, 0.1075, 0.1526, 0.3230, 0.0620, 0.1686],
[0.1157, 0.2006, 0.1414, 0.0668, 0.3477, 0.1279],
[0.1776, 0.1133, 0.0975, 0.1690, 0.1191, 0.3236]])Ich versuche mich mal an einer Intepretation oder Ergebnisse. Dabei darf man nicht vergessen, dass es sich um ein sehr stark vereinfachtes, konstruiertes Beispiel handelt, um das Prinzip darzulegen.
Aufmerksamkeitsgewichte
Die Aufmerksamkeitsgewichte, repräsentiert durch die Matrix, quantifizieren die Relevanz jedes einzelnen Wortes im Kontext des gesamten Satzes. Höhere Werte signalisieren dabei eine stärkere Beziehung zwischen dem “Query”-Wort (der Zeile) und dem “Key”-Wort (der Spalte).
Auf der Diagonalen der Matrix kann man ablesen, wie stark die Beziehung eines Wortes zu sich selbst ist. Abseits davon zeigt die Matrix die Stärke der Beziehung des Query-Wortes zu den anderen Wörtern im Satz.
Betrachten wir das Wort May (erste Zeile): Es hat eine vergleichsweise starke Beziehung zu sich selbst () und eine eher schwache Beziehung zum Wort the (). Interessanterweise zeigt May auch relativ hohe Gewichte zu be () und you (). Dies könnte darauf hindeuten, dass das Modell diese Wörter als wichtig für den Kontext von May im Satz “May the force be with you.” erachtet.
Für force (dritte Zeile) sehen wir ebenfalls eine starke Selbstbeziehung (), aber auch relativ starke Beziehungen zu the () und be (). Dies illustriert, wie das Modell semantische oder syntaktische Zusammenhänge zwischen den Wörtern erkennt und entsprechend gewichtet. Die Aufmerksamkeitsmatrix ermöglicht es uns, zu analysieren, welche Wörter das Modell als besonders relevant für die Interpretation eines bestimmten Wortes im Satz erachtet.
Kontextvektor
Die gewichtete Summe der Value-Vektoren bildet den Kontextvektor. Er erfasst unter Berücksichtigung der Beziehungen zwischen den Wörtern die relevanten Informationen aus dem gesamten Satz. Die Aufmerksamkeitsgewichte bestimmen dabei, wie stark die Value-Vektoren der einzelnen Wörter zum Kontextvektor beitragen. Auf diese Weise entsteht eine kontextuelle Repräsentation jeden Wortes, die durch die Beziehungen zu anderen Wörtern im Satz geprägt ist.
Im Beispiel wird der Kontextvektor für May stark von den Value-Vektoren der Wörter beeinflusst, denen May hohe Aufmerksamkeitsgewichte zuweist (z.B. be und you wie oben beobachtet). Der Kontextvektor für the hingegen wird möglicherweise stärker durch die Value-Vektoren von force und with dominiert, da es hier hohe Aufmerksamkeitsgewichte gab.
Wichtig ist: Wir können die konkreten Einflüsse der einzelnen Wörter nicht direkt an den Zahlen im resultierenden Kontextvektor ablesen. Diese Information entnehmen wir der vorher berechneten Aufmerksamkeitsmatrix. Um die Qualität der Kontextvektoren und die Beziehung zu den Aufmerksamkeitsgewichten besser zu verstehen, können wir wieder die Kosinus-Ähnlichkeit ins Spiel bringen. Sie hilft zu überprüfen, wie sich die resultierenden Kontextvektoren zueinander ähneln und wie dies mit den gelernten Aufmerksamkeitsgewichten zusammenhängt.
def kosinus_aehnlichkeit(vektor1, vektor2):
return F.cosine_similarity(vektor1.unsqueeze(0), vektor2.unsqueeze(0)).item()
def vergleiche_vektoren(kontextvektoren, aufmerksamkeitsmatrix, wortliste, wort_index):
"""Vergleicht den Kontextvektor eines Wortes mit den Kontextvektoren der anderen Wörter,
wobei die Aufmerksamkeitsgewichte berücksichtigt werden."""
ergebnisse = {}
for anderes_wort_index in range(len(kontextvektoren)):
if wort_index != anderes_wort_index:
aehnlichkeit = kosinus_aehnlichkeit(kontextvektoren[wort_index], kontextvektoren[anderes_wort_index])
ergebnisse[wortliste[anderes_wort_index]] = {
"Ähnlichkeit": aehnlichkeit,
"Aufmerksamkeitsgewicht": aufmerksamkeitsmatrix[wort_index, anderes_wort_index].item()
}
return ergebnisse
# Eingabesatz
input_sentence = "May the force be with you"
wortliste = input_sentence.split()
# Beispielaufruf
ergebnisse_may = vergleiche_vektoren(kontextvektoren, aufmerksamkeitsmatrix, wortliste, 0)
ergebnisse_the = vergleiche_vektoren(kontextvektoren, aufmerksamkeitsmatrix, wortliste, 1)
# Ausgabe der Ergebnisse mit Tabbing
print("Vergleich für 'May':")
print(" Wort\t\tÄhnlichkeit\tAufmerksamkeitsgewicht")
for wort, daten in ergebnisse_may.items():
print(f" {wort}\t\t{daten['Ähnlichkeit']:.4f}\t\t{daten['Aufmerksamkeitsgewicht']:.4f}")
print("\nVergleich für 'the':")
print(" Wort\t\tÄhnlichkeit\tAufmerksamkeitsgewicht")
for wort, daten in ergebnisse_the.items():
print(f" {wort}\t\t{daten['Ähnlichkeit']:.4f}\t\t{daten['Aufmerksamkeitsgewicht']:.4f}")Vergleich für 'May':
Wort Ähnlichkeit Aufmerksamkeitsgewicht
the 0.9387 0.0651
force 0.9561 0.1020
be 0.9919 0.1955
with 0.9491 0.1128
you 0.9933 0.1859
Vergleich für 'the':
Wort Ähnlichkeit Aufmerksamkeitsgewicht
May 0.9387 0.0622
force 0.9944 0.2064
be 0.9542 0.1077
with 0.9913 0.1867
you 0.9596 0.1133Die Ergebnisse des Skripts deuten auf eine Korrelation zwischen der semantischen Ähnlichkeit (gemessen durch die Kosinus-Ähnlichkeit der Kontextvektoren) und den Aufmerksamkeitsgewichten hin. Wörter, die vom Modell als relevanter für den Kontext eines bestimmten Query-Wortes erachtet werden (erkennbar an hohen Aufmerksamkeitsgewichten), weisen tendenziell auch eine höhere semantische Ähnlichkeit in ihren resultierenden Kontextvektoren auf. Dies wird beispielsweise durch den Vergleich von May mit be und you (hohe Ähnlichkeit und hohe Gewichte) versus May mit the (geringere Ähnlichkeit und geringeres Gewicht) veranschaulicht.
Die dynamische Gewichtung durch den Aufmerksamkeitsmechanismus ermöglicht es dem Modell, den Kontext eines jeden Wortes präzise zu verstehen und relevante Informationen für die Weiterverarbeitung zu extrahieren. Der resultierende Kontextvektor dient somit als angereicherte Grundlage für nachfolgende Schichten im Transformer-Modell. Um diese dynamische Gewichtung besser zu verstehen, stellt sich die Frage: Warum zeigen bestimmte Wörter in dieser Matrix eine stärkere Beziehung zueinander als andere? Dies liegt an den während des Trainings gelernten Gewichtungsmatrizen (, , ), die die Beziehungen in den -, - und -Vektoren so formen, dass sinnvolle Abhängigkeiten erkannt werden.
Bis hierher haben wir die Funktionsweise eines Single-Head-Attention-Blocks beleuchtet. Wir haben gesehen, wie der Eingabesatz in Tokens zerlegt und in Embeddings umgewandelt wird. Aus diesen Eingabe-Embeddings werden die Query-, Key- und Value-Matrizen abgeleitet. Mit diesen Matrizen werden Aufmerksamkeitsgewichte berechnet, die dann verwendet werden, um die Value-Matrizen zu gewichten und kontextualisierte Vektoren (Kontextvektoren) zu erzeugen.
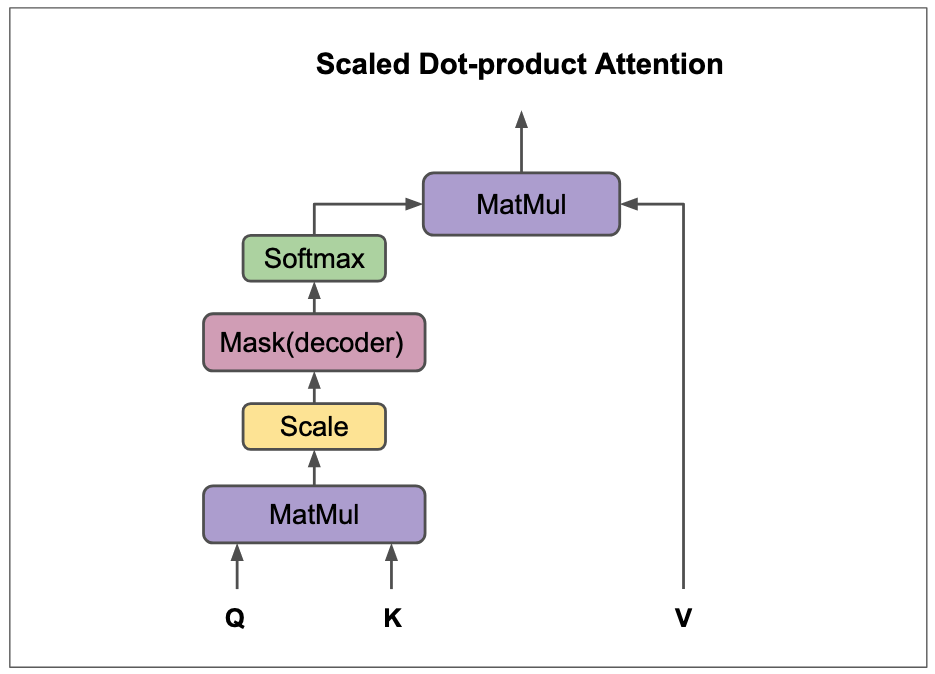
An dieser Stelle fehlt ein entscheidender Aspekt, um von einem Single-Head-Attention-Block zu einem Multi-Head-Attention-Block zu gelangen: Die Aufteilung in mehrere “Attention Heads”. Dies ist ein zentrales Konzept, um die Leistungsfähigkeit von Transformern weiter zu steigern.
Multi-Head Attention: Mehrere “Sichtweisen” auf den Kontext
Bisher haben wir den Single-Head Attention-Mechanismus betrachtet, bei dem jedes Wort im Satz seine Aufmerksamkeit auf die anderen Wörter richtet und einen einzelnen Kontextvektor bildet. Das ist vergleichbar mit einer Person, die einen Text liest und versucht, die Bedeutung jedes Wortes im Gesamtkontext zu verstehen – aber nur aus einer einzigen Perspektive.
Der Multi-Head Attention-Mechanismus ist eine geniale Erweiterung dieses Konzepts. Stell dir vor, dieselbe Person liest den Text, hat aber nun verschiedene “Brillen” oder “Perspektiven” auf. Jede Brille (oder eben jeder “Attention Head”) erlaubt es, unterschiedliche Aspekte der Beziehungen zwischen den Wörtern zu erkennen und zu fokussieren.
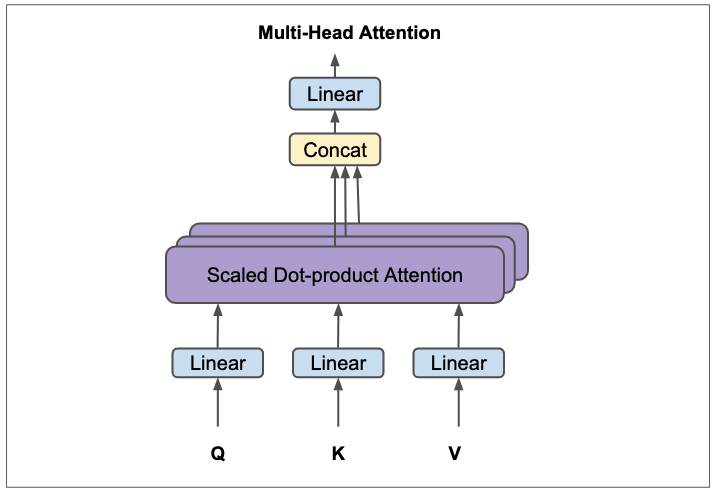
Warum mehrere Köpfe (Heads)?
Der Hauptgrund für Multi-Head Attention ist, dass ein einzelner Attention Head möglicherweise nicht ausreicht, um die vielfältigen Beziehungen in einem Satz vollständig zu erfassen. Ein Wort kann gleichzeitig:
- Syntaktische Beziehungen zu anderen Wörtern haben (z.B. Subjekt-Verb-Beziehung: “Die Katze frisst die Maus”).
- Semantische Beziehungen aufweisen (z.B. Synonyme, Hyperonyme: “Fluss” und “Strom”, oder “Tier” als Oberbegriff für “Katze”).
- Referentielle Beziehungen herstellen (z.B. Pronomen, die sich auf frühere Nomen beziehen: “Der Junge spielte, er war glücklich.”).
- Informationen über unterschiedliche Bedeutungsaspekte aufnehmen (z.B. “Bank” als Geldinstitut vs. Sitzgelegenheit: “Ich gehe zur Bank.” vs. “Ich sitze auf der Bank.”).
Jeder “Head” kann sich auf einen dieser Aspekte spezialisieren oder eine andere Art von Aufmerksamkeit lernen, wodurch das Modell ein ausgiebigeres und umfassenderes Verständnis des Eingabetextes erhält. Es ist, als würden mehrere “Experten” gleichzeitig auf verschiedene Aspekte des Satzes schauen und ihre Erkenntnisse kombinieren.
Die Kernidee
Die Eingabe-Embeddings werden nicht nur einmal in Query-, Key- und Value-Matrizen projiziert, sondern mehrere Male parallel – für jeden Head separat. Jedes dieser projizierten Sets von , , wird dann durch einen eigenen, unabhängigen Scaled Dot-Product Attention-Mechanismus geleitet. Die Ergebnisse dieser unabhängigen Attention-Berechnungen werden dann zusammengeführt (konkateniert) und erneut transformiert, um die finale Ausgabe des Multi-Head Attention Layers zu bilden.
Visuelle Analogie
Ich versuche es mit einer weiteren Analogie, einem weiteren Beispiel.
- Single-Head: Ein einziger Filter, der ein Bild analysiert und alle Merkmale gleichzeitig versucht zu finden, was zu einer “Durchschnittsansicht” führen kann.
- Multi-Head: Mehrere verschiedene Filter, die parallel arbeiten und jeweils auf spezifische Merkmale spezialisiert sind. Ein Filter sucht nach Kanten, ein anderer nach Farben, ein dritter nach Texturen usw. Die Ergebnisse dieser spezialisierten Filter werden dann kombiniert, um ein umfassenderes Verständnis des Bildes zu erhalten.
Mathematische Darstellung des Multi-Head Attention
Die Formel für Multi-Head Attention sieht wie folgt aus:
Wobei jeder einzelne “Head” wie folgt berechnet wird:
Und die -Funktion (Scaled Dot-Product Attention) die wir bereits kennen:
Hierbei gilt:
- : Die ursprünglichen Query-, Key- und Value-Matrizen, abgeleitet von den Eingabe-Embeddings.
- : Projektionsmatrizen für den -ten Attention Head. Jede dieser Matrizen hat eine Dimension von , wobei die Dimension der Eingabe-Embeddings und die Dimension der Query/Key-Vektoren für einen Head ist. Oft ist .
- : Die Anzahl der Attention Heads.
- : Eine finale lineare Projektionsmatrix, die die konkatenierten Ausgaben der Heads auf die ursprüngliche Modelldimension zurückprojiziert.
Mehr zu den Formeln kann man im Paper nachlesen. Ab Kapitel 3.2.1 wird es dahingehend spannend.
Schritte im Multi-Head Attention:
-
Lineare Projektionen für jeden Head: Für jeden der Attention Heads werden die Eingabe-Embeddings (oder die Ausgabe des vorherigen Layers) parallel in separate Query (), Key () und Value () Matrizen projiziert. Dies geschieht durch Multiplikation mit den spezifischen Gewichtungsmatrizen für jeden Head. Der Clou hierbei ist, dass jeder Head seine eigenen, unabhängigen Projektionen lernt. Dadurch kann jeder Head einen anderen Aspekt der Eingabedaten fokussieren.
-
Berechnung der skalierten Punktprodukt-Aufmerksamkeit: Für jedes Paar () wird die Skalierte Punktprodukt-Aufmerksamkeit separat berechnet. Das Ergebnis jedes Heads ist ein Satz von kontextualisierten Vektoren ().
-
Konkatenation der Head-Ausgaben: Die Ausgaben der einzelnen Attention Heads () werden nebeneinandergelegt (konkateniert), wodurch eine einzige breitere Matrix entsteht.
-
Finale lineare Projektion: Die konkatenierte Matrix wird dann durch eine weitere gelernte lineare Transformationsmatrix projiziert. Diese finale Transformation bringt die Dimension der Ausgabe wieder auf die gewünschte Modelldimension und ermöglicht es dem Modell, die kombinierten Informationen der verschiedenen Heads zu integrieren.
Praktisches Beispiel
Es wird wieder Zeit für ein praktisches Beispiel mit Code. Um das Konzept des Multi-Head Attention zu verdeutlichen, bauen wir auf unserem vorherigen Beispiel auf. Wir werden die Logik des Aufmerksamkeitsmechanismus in einer neuen Funktion anpassen, um zu zeigen, wie mehrere Heads parallel arbeiten und ihre Ergebnisse kombinieren.
Annahmen für das Beispiel
- Eingabe-Embeddings: Wie zuvor werden wir auch weiterhin mit Eingabe-Embeddings für den Satz
May the force be with youverwenden. - Anzahl Heads (): Ich wähle eine kleine, aber verständliche Anzahl, z.B. Heads.
- Dimension pro Head (): Wenn die Dimension des Eingabe-Embedding ist und wir wählen, dann ist die Dimension pro Head . Jeder Head wird also mit 5-dimensionalen , , Vektoren arbeiten.
- Das ergibt sich aus der Überlegung, dass die Gesamt-Dimensionalität der Ausgaben der Heads () wieder der ursprünglichen Modelldimension () entsprechen soll, bevor die finale Projektion angewendet wird. Dies stellt sicher, dass die Dimension im gesamten Transformer-Block konsistent bleiben.
- Gewichtungsmatrizen: Für das Beispiel werde ich einfache, zufällig initialisierte Gewichtungsmatrizen erstellen. In einem echten, trainierten Modell wären diese Matrizen sorgfältig gelernt worden, um spezifische linguistische Muster zu erkennen.
Dann legen wir mal los.
1. Initialisieren der Gewichtungsmatrizen für jeden Head
Jeder Head benötigt eigene Projektionsmatrizen:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import torch
import torch.nn.functional as F
import numpy as np
torch.manual_seed(42) # You can replace 42 with any integer of your choice
# Beispiel-Embeddings (6 Wörter, 10 Dimensionen)
word_embeddings = {
"May": torch.tensor([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]),
"the": torch.tensor([1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1]),
"force": torch.tensor([0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 0.1, 0.2, 0.3, 0.4]),
"be": torch.tensor([0.2, 0.4, 0.6, 0.8, 1.0, 0.1, 0.3, 0.5, 0.7, 0.9]),
"with": torch.tensor([0.9, 0.7, 0.5, 0.3, 0.1, 1.0, 0.8, 0.6, 0.4, 0.2]),
"you": torch.tensor([0.3, 0.1, 0.9, 0.7, 0.5, 0.2, 1.0, 0.8, 0.6, 0.4])
}
input_sentence_list = ["May", "the", "force", "be", "with", "you"]
input_embeddings = torch.stack([word_embeddings[word] for word in input_sentence_list])
d_model = input_embeddings.shape[1] # Dimension der Eingabe-Embeddings (hier 10)
num_heads = 2 # Anzahl der Attention Heads
d_k = d_model // num_heads # Dimension der Q, K, V Vektoren pro Head (hier 5)
W_Q = torch.randn(num_heads, d_model, d_k) # (heads, d_model, d_k)
W_K = torch.randn(num_heads, d_model, d_k)
W_V = torch.randn(num_heads, d_model, d_k)
W_O = torch.randn(d_model, d_model) # Finale Projektionsmatrix2. Implementierung der Multi-Head Attention Logik
Als nächstes folgt die Funktion, die die oben beschriebenen Schritte des Multi-Head-Attention Mechanismus durchführt.
def multi_head_attention(input_embeddings, W_Q, W_K, W_V, W_O, num_heads, d_k, mask=None):
# input_embeddings wird hier mit Batch-Dimension erwartet: (batch_size, seq_len, d_model)
batch_size, seq_len, d_model = input_embeddings.shape
heads_output = []
attention_matrices = []
for i in range(num_heads):
# Projiziere für den aktuellen Head
# (batch_size, seq_len, d_model) @ (d_model, d_k) -> (batch_size, seq_len, d_k)
Q_i = torch.matmul(input_embeddings, W_Q[i])
K_i = torch.matmul(input_embeddings, W_K[i])
V_i = torch.matmul(input_embeddings, W_V[i])
# 2. Berechnung der skalierten Punktprodukt-Aufmerksamkeit für head_i
# scores: (batch_size, seq_len, seq_len)
scores = torch.matmul(Q_i, K_i.transpose(-2, -1)) / (d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention_weights_i = F.softmax(scores, dim=-1)
# head_i: (batch_size, seq_len, d_k)
head_i = torch.matmul(attention_weights_i, V_i)
heads_output.append(head_i)
attention_matrices.append(attention_weights_i)
# 3. Konkatenation der Head-Ausgaben
# heads_output ist eine Liste von (batch_size, seq_len, d_k) Tensoren
# concated_heads: (batch_size, seq_len, num_heads * d_k) = (batch_size, seq_len, d_model)
concated_heads = torch.cat(heads_output, dim=-1)
# 4. Finale lineare Projektion
# output: (batch_size, seq_len, d_model) @ (d_model, d_model) -> (batch_size, seq_len, d_model)
output = torch.matmul(concated_heads, W_O)
return output, attention_matrices# Aufruf der Multi-Head Attention Funktion
input_embeddings_batched = input_embeddings.unsqueeze(0)
output_mha, attention_matrices_mha = multi_head_attention(
input_embeddings_batched, W_Q, W_K, W_V, W_O, num_heads, d_k
)
print("\nAusgabe des Multi-Head Attention Layers (Kontextvektoren):\n", output_mha.squeeze(0)) # squeeze(0) entfernt die Batch-Dimension
print(f"\nAnzahl der Aufmerksamkeitsmatrizen (entspricht num_heads): {len(attention_matrices_mha)}")
print("\n--- Visualisierung der Aufmerksamkeitsmatrizen ---")
plt.figure(figsize=(num_heads * 6, 6)) # Passt die Figurgröße dynamisch an die Anzahl der Heads an
for i, attn_matrix in enumerate(attention_matrices_mha):
plt.subplot(1, num_heads, i + 1)
# KORRIGIERT: squeeze(0) um die Batch-Dimension zu entfernen
df_attn = pd.DataFrame(attn_matrix.squeeze(0).detach().numpy(), index=input_sentence_list, columns=input_sentence_list)
sns.heatmap(df_attn, annot=True, cmap="YlGnBu", fmt=".2f", linewidths=.5, linecolor='gray')
plt.title(f"Aufmerksamkeitsgewichte Head {i+1}")
plt.xlabel("Keys (worauf geachtet wird)")
plt.ylabel("Queries (welches Wort beachtet)")
plt.tight_layout()
plt.show()Ausgabe des Multi-Head Attention Layers (Kontextvektoren):
tensor([[-6.3872, 1.9858, 2.1712, 2.7969, -2.1122, -5.8285, -3.3943, -1.7054,
-2.6450, 3.8029],
[-6.0595, 2.2669, 2.7205, 3.5506, -2.4773, -6.7691, -3.6894, -2.3192,
-2.7402, 5.1961],
[-4.6440, 1.6299, 3.9077, 5.0117, -1.8828, -6.0060, -3.2956, -3.3168,
-2.5437, 4.9490],
[-5.7771, 2.0586, 2.5875, 3.0803, -1.6768, -5.7386, -3.5614, -2.2284,
-2.6754, 4.2769],
[-6.4755, 2.3926, 2.5579, 3.2462, -2.8572, -6.9736, -3.5434, -1.9716,
-2.7969, 5.1418],
[-6.8217, 3.0510, 3.1547, 2.3845, -1.8317, -6.1681, -2.8469, -1.6187,
-2.7340, 4.0441]])
Anzahl der Aufmerksamkeitsmatrizen (entspricht num_heads): 2
--- Visualisierung der Aufmerksamkeitsmatrizen ---![]()
Interpretation der Ergebnisse
Wichtiger Hinweis: Nochmals zur Erinnerung… Die Gewichtungsmatrizen , , und wurden zufällig initialisiert und spiegeln daher keine sinnvollen linguistischen oder semantischen Bedeutungen wider. Ein trainiertes Modell würde diese Matrizen jedoch so lernen, dass sie tatsächlich relevante Abhängigkeiten erfassen. Der Zweck dieser Demonstration ist es, das Prinzip zu zeigen, dass jeder Head eine andere Verteilung der Aufmerksamkeit lernen kann.
Aufmerksamkeitsmatrix Head 1
print(pd.DataFrame(attention_matrices_mha[0].squeeze(0).detach().numpy(), index=input_sentence_list, columns=input_sentence_list)) May the force be with you
May 0.068118 0.181340 0.071635 0.027055 0.456570 0.195282
the 0.015012 0.246116 0.019410 0.006160 0.599809 0.113493
force 0.007348 0.470308 0.094195 0.009372 0.368718 0.050059
be 0.054408 0.292597 0.065859 0.040474 0.393329 0.153334
with 0.018118 0.147041 0.020352 0.003969 0.671181 0.139338
you 0.106796 0.130137 0.028468 0.034135 0.407147 0.293316Beobachtungen Head 1
- In dieser Matrix ist eine starke Konzentration der Aufmerksamkeit auf das Wort
with(Spalte 5) zu erkennen. Viele Wörter (May,the,be,with,you) richten einen großen Teil ihrer Aufmerksamkeit aufwith. - Besonders
withselbst hat den höchsten Aufmerksamkeitswert auf sich selbst (). In trainierten Modellen ist dies oft bei zentralen Elementen in Phrasen oder bei Wörtern der Fall, die eine wichtige Rolle bei der Verknüpfung spielen. - Ebenfalls vergleichsweise deutlichere Aufmerksamkeitswerte weist die Spalte für
theauf. Wörter wieforce() undbe() richten hier signifikante Aufmerksamkeit hin. - Selbst-Aufmerksamkeit (Diagonale): Die Werte auf der Diagonalen zeigen, wie stark ein Wort auf sich selbst achtet.
withundthehaben hier relativ hohe Werte, währendMay() undforce() beispielsweise weniger Aufmerksamkeit auf sich selbst richten. - Das Wort
you(letzte Zeile) verteilt seine Aufmerksamkeit relativ gleichmäßig auf andere Wörter, wobeiwithimmer noch der stärkste Fokus ist ().
Mögliche Hypothese/Interpretation Head 1
Dieser Head könnte darauf spezialisiert sein, lokale Abhängigkeiten und grammatische Strukturen wie Präpositional- oder Nomenphrasen zu erfassen. Die starke Konzentration auf with und the könnte darauf hindeuten, dass dieser Head hilft, Phrasen wie with you oder the force als zusammenhängende Einheiten zu identifizieren. Es scheint auch eine Tendenz zu haben, sich auf Funktionale Wörter (wie Artikel oder Präpositionen) zu konzentrieren, die oft wichtige syntaktische Rollen spielen.
Aufmerksamkeitsmatrix Head 2
print(pd.DataFrame(attention_matrices_mha[1].squeeze(0).detach().numpy(), index=input_sentence_list, columns=input_sentence_list)) May the force be with you
May 0.339670 0.036311 0.029780 0.072609 0.169863 0.351766
the 0.549202 0.000667 0.000758 0.028736 0.012748 0.407889
force 0.651215 0.000264 0.000342 0.038280 0.004499 0.305399
be 0.405897 0.003060 0.001443 0.031975 0.038848 0.518777
with 0.521837 0.008986 0.017760 0.074093 0.063290 0.314033
you 0.522649 0.000785 0.000491 0.012670 0.032367 0.431039Beobachtungen Head 2
- Dieser Head zeigt eine sehr starke Konzentration der Aufmerksamkeit auf das erste Wort des Satzes,
May(Spalte 0). Fast alle anderen Wörter (the,force,be,with,you) richten einen Großteil ihrer Aufmerksamkeit aufMay. - Gleichzeitig gibt es auch eine deutliche Aufmerksamkeit auf das letzte Wort
you(Spalte 5). Viele Wörter schauen sowohl aufMayals auch aufyou. - Die Werte in den mittleren Spalten (
the,force,be,with) sind weitestgehend sehr niedrig, was auf eine geringere Aufmerksamkeit auf diese Wörter hindeutet, wenn sie als Keys dienen. Mayundyouweisen zudem eine hohe Selbst-Aufmerksamkeit auf.
Mögliche Hypothese/Interpretation Head 2
Dieser Head könnte sich auf die Endpunkte der Sequenz oder auf globale Beziehungen spezialisiert haben. Das Muster deutet darauf hin, dass es versucht, den Satzanfang (May) und das Satzende (you) stark miteinander in Verbindung zu bringen, möglicherweise um den Gesamtkontext einer Aussage zu erfassen oder die Beziehungen zwischen Satzteilen zu erkennen, die weit voneinander entfernt sind. Dies ist ein typisches Merkmal von Transformer-Modellen, die im Gegensatz zu RNNs in der Lage sind, auch weitreichende Abhängigkeiten direkt zu modellieren.
Zusammenfassung Multi-Head Attention
Der Vergleich der beiden Matrizen macht den Kern des Multi-Head Attention Mechanismus deutlich:
- Head 1 scheint sich auf lokale Phrasen und Funktionale Wörter (
with,the) zu konzentrieren. Es ist, als würde dieser Head die unmittelbare Grammatik und die Beziehungen zu direkten Nachbarn im Blick behalten. - Head 2 hingegen konzentriert sich auf die Anfangs- und Endpunkte des Satzes und ignoriert die Details in der Mitte weitgehend. Dieser Head könnte dazu dienen, übergeordnete Strukturen oder globale Abhängigkeiten über die gesamte Satzlänge zu erfassen.
Obwohl diese spezifischen Muster in unserem Beispiel zufällig entstanden sind, ist die Diversität der Aufmerksamkeitsmuster genau das, was das Multi-Head Design so mächtig macht. Jeder Head lernt (während des Trainings) eine andere Art von Beziehung zwischen den Wörtern zu identifizieren und zu gewichten. Durch die Konkatenation der Ausgaben und die finale lineare Projektion werden diese verschiedenen Perspektiven zu einer reichhaltigeren, mehrdimensionalen und kontextuell angereicherten Repräsentation jedes Wortes im Satz verschmolzen.
Fazit und Ausblick auf Teil 2
Wie wir nun an den zugegebener Maßen einfachen Beispielen gesehen haben, ist der Multi-Head Attention Mechanismus weit mehr als nur eine einfache Gewichtung von Wörtern. Er ermöglicht es dem Transformer, parallel verschiedene Arten von Beziehungen und Kontexten in den Daten zu erfassen. Jeder Head (in GPT-3 sind es z.B. 96 Heads!) kann sich auf unterschiedliche semantische oder syntaktische Aspekte konzentrieren, wodurch eine viel reichhaltigere und nuanciertere Repräsentation jedes Wortes im Satz entsteht. Die Fähigkeit, diese vielfältigen Sichtweisen zu integrieren, ist ein Schlüssel zur Leistungfähigkeit der Transformer-Architektur.
Doch trotz dieser Aufmerksamkeitsmechanismen fehlen dem Modell noch entscheidende Elemente, auf die ich im zweiten Teil eingehen möchte, um ein vollständiges Bild zu erhalten:
- Der Attention-Mechanismus selbst ist positionsagnostisch, das heißt, er weiß nichts über die Reihenfolge der Wörter. Um das zu beheben, integrieren Transformer das sogenannte Positions-Encoding, das die sequentielle Information in die Embeddings injiziert.
- Die durch Attention gewonnenen kontextualisierten Informationen müssen weiterverarbeitet und transformiert werden, wofür Feed-Forward-Netzwerke benötigt werden.
- Für ein stabiles Training der tiefen neuronalen Architekturen sind Residual Connections und Layer Normalization unverzichtbar, da sie dem Gradientenfluss helfen und die Konvergenz beschleunigen.
- Und zuletzt fügen sich all diese Komponenten in die übergeordnete Struktur des Transformer Encoder und Decoder ein, in denen spezielle Masken eine kritische Rolle spielen (z.B. die anfangs erwähnte Maske, die das “Spicken” in zukünftige Tokens verhindert).
Im nächsten Teil, werde ich mir genau diese Themen ansehen und versuchen zu beleuchten.