From the last article, we know that basically all common artificial intelligence methods can be classified as weak AI. And these methods and techniques can be further subdivided. Today, we want to focus on this subdivision.
In fact, when I talk about artificial intelligence, we are dealing with machine learning (ML) — a category of artificial intelligence. ML can be further subdivided into supervised, unsupervised, and reinforcement learning. We will deal with these three and their respective subcategories today

Source Researchgate
As before, the topics are much more extensive. I will try to present them in a greatly simplified form.
Supervised Learning
In supervised learning, labeled data must be provided to the ML algorithm. Through the so-called features (input data of the model) and the associated target values or observation variables (output data of the model), concrete correlations are learned during training and, with the help of these correlations or this model, predictions for new input data are then made during testing or validation. This process requires a good and large database in order to learn the necessary correlations and make accurate predictions. This involves a high level of human effort and is not possible for all data sets. The following examples of classification give an idea of how much effort is involved.

Two categories of supervised learning, image from whataftercollege
Classification
In classification, models are trained to divide the input data into fixed categories. One example, which we will also cover in a later article with Python code, is the publicly available MNIST database, which consists of examples in the training dataset and examples in the test dataset. These are handwritten digits stored in pixel grayscale images. Each image is linked to a unique label or observation variable.

MNIST dataset, image from Wikipedia
The training data set is now used to train the model (often a convolutional neural network) and the test data set is used to test and validate the model. For this purpose, each image is fed into the model, which makes a prediction (classifying it into one of the ten categories/digits, see Softmax Activationfunction). During training, the model is constantly updated to improve this prediction. We will also take a closer look at this process in Python code in a concrete example.
Further examples are:
- Fashion-MNIST – a database of images of clothing items, also divided into ten categories
- food101 – a database of images of food divided into 101 categories
- Cats vs. Dogs – a database of images of dogs and cats, and therefore two categories
The following algorithms are used particularly frequently:
- Logistic regression
- K-nearest neighbors (KNN)
- Support Vector Machines (SVM)
- Naive Bayes
- Decision trees and derived methods such as random forests or gradient boosted trees
- Artificial neural networks (e.g., convolutional neural networks)
Regression
Regression is often used to identify trends or make specific predictions. Input data includes, for example, age, salary, or prices, which the model uses to learn correlations and make predictions. A frequently cited example is the Boston Housing Dataset. We will also work with this dataset in an upcoming article and train a model.

Boston skyline, image from Pixabay
The Boston Housing dataset is a real dataset that was collected in the 1970s and contains 14 features or characteristics relating to house prices in Boston, in addition to the house prices themselves. The dataset contains 506 entries. This dataset can be used to train a model that can predict or estimate prices based on features (e.g., crime rate, number of rooms, etc.). Unlike classification, where a defined number of categories determine the output of the model, a regression algorithm can deliver any output value.
The following algorithms are particularly frequently used for regression:
- Linear regression
- Artificial neural networks
- Decision trees and derived methods such as random forests or gradient boosted trees
Unsupervised learning
Unlike supervised learning, unsupervised learning does not require labeled data. The algorithm attempts to recognize patterns and structures in the data. These patterns can only be recognized using the features themselves, because there are no observation variables and the data is not labeled.
Therefore, generating data sets for unsupervised learning does not require a great deal of human effort because the entries do not need to be labeled.
Clustering/segmentation
Clustering or segmentation is used to sort data entries into identical groups and is considered the most important method of unsupervised learning. In clustering, data is grouped so that entries with identical or similar characteristics are assigned to a group.
The K-means algorithm is often used for this classification, where k describes the number of clusters.
 Cluster analysis with k = 3, image from Wikipedia
Cluster analysis with k = 3, image from Wikipedia
There is also hierarchical clustering, density-based spatial clustering of applications with noise (DBSCAN), and Gaussian mixture models (GMM).
Dimensionality reduction/compression
Dimensionality reduction serves to reduce the number of features in the data set to those that are essential and relevant to the task at hand. This method is often used to reduce so-called overfitting. In overfitting, the model learns (too) specifically from the training data set and is then unable to make a good prediction for further data. By reducing the number of features, the model has to learn more generally and the probability of overfitting decreases.
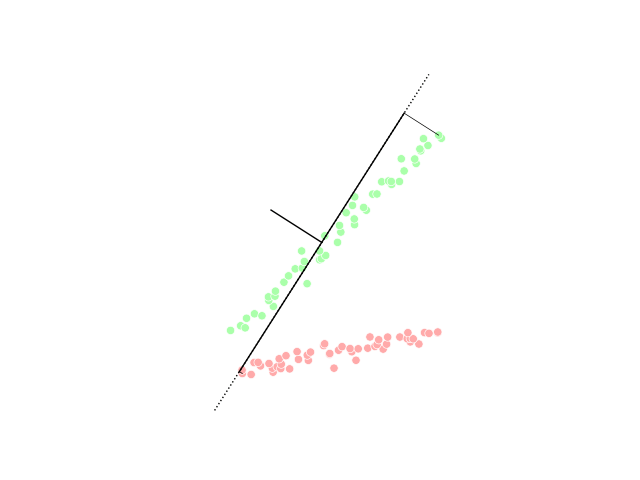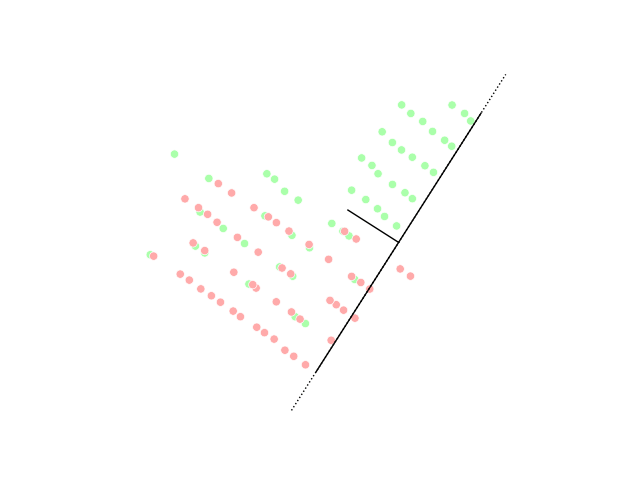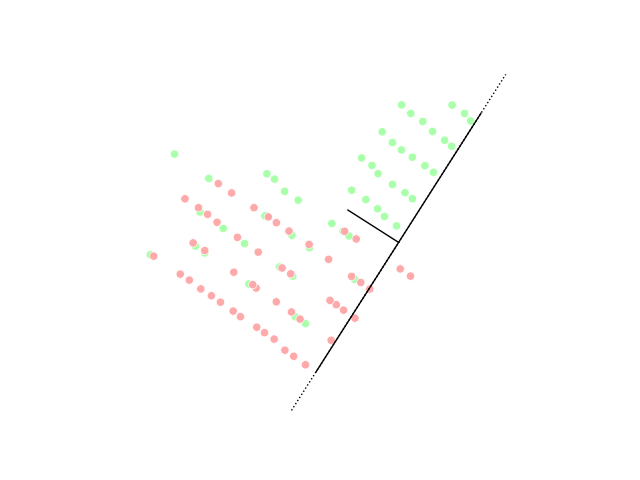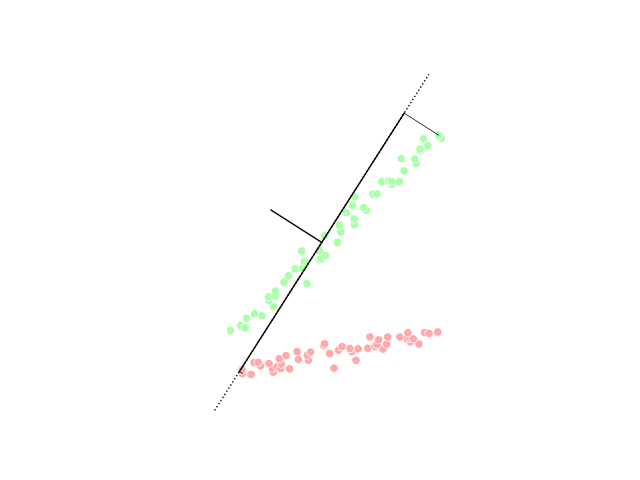 PCA visualization, image from Wikipedia
PCA visualization, image from Wikipedia
The following methods are also frequently used:
- PCA - Principal Components Analysis
- KNN - K-Nearest Neighbors
- NMF - Non Negative Matrix Factorization
Reinforcement Learning
In addition to supervised and unsupervised learning, there is also reinforcement learning. Reinforcement learning must also manage without labeled data sets, without observation variables. Instead, the reinforcement learning algorithm learns through interaction with the environment.
Reinforcement learning principle, image from researchgate
I would like to use Breakout as an example to describe the principle of reinforcement learning. Some of you may still remember this Atari game: You try to deflect the ball back by moving the bar left and right and destroy the rainbow-colored wall in the upper third of the screen. You receive points for the latter. If you fail to return the ball, the game is lost.

In reinforcement learning, the algorithm is given the possible actions (starting the game, doing nothing, bar to the left, bar to the right) and is rewarded for every good action or punished for bad actions, such as losing the game. This collection of rewards and punishments, known as the policy, ensures that the initially dumb algorithm learns what it (the agent) needs to do to increase its score or win the game. The game itself is the so-called environment with which the agent interacts in order to collect points. In this way, the agent learns how the game works and even learns entire strategies. But more on that another time.
Again, I have simplified it greatly in order to provide an overview. I will provide a more detailed description with Python code in a later article.